In class it was discussed that right BVH is better than the left because it has more empty space. But, the way I see it is that we finally come down to the leaf node. So, I think the major factor in the computational cost is the number of primitives in the target leaf node. Here the leaf nodes are same in both BVH's. So, both the tree are same in terms of computational cost. Is this right? Could someone please explain if the logic is flawed.
anonymous_panda
I think for the one on the right, one can stop early once it is determined that the line neither intersect B nor C. For the one on the left any line that crosses A will always intersect B & C, so you can not stop early.
nrauen
Is there a way for us to quicken the computations by creating algorithms that create smarter boxes or must it be done on a case by case basis?
siliangl
I understand the example of sorting numbers in the previous slide, but what does it mean to sort triangles? Moreover, for BVH algorithm, do you always loop through all the triangles first and construct such a tree based on the sorting algorithm before you do anything else?
kye
@siliangl The sorting is a metaphor for preprocessing the data / building an acceleration data structure to support certain repeated operations, in this case finding the first ray-triangle intersection.
To construct a BVH, you might not "loop through" all the triangles first in order; you might partition them or group them first before getting to the leaf nodes. BVH construction doesn't explicitly use a "sorting" algorithm as in the previous slide, which was again just a metaphor.
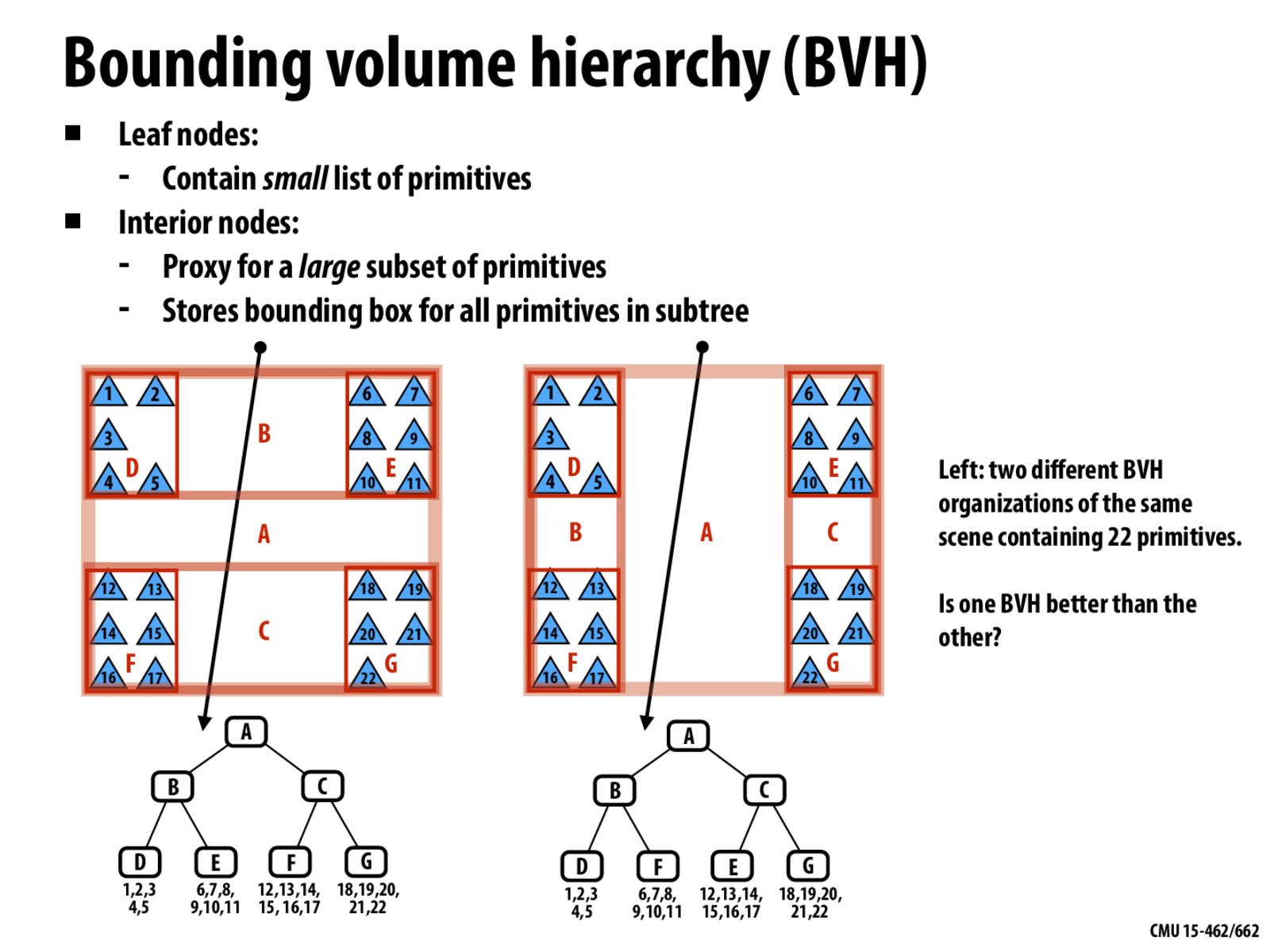
In class it was discussed that right BVH is better than the left because it has more empty space. But, the way I see it is that we finally come down to the leaf node. So, I think the major factor in the computational cost is the number of primitives in the target leaf node. Here the leaf nodes are same in both BVH's. So, both the tree are same in terms of computational cost. Is this right? Could someone please explain if the logic is flawed.
I think for the one on the right, one can stop early once it is determined that the line neither intersect B nor C. For the one on the left any line that crosses A will always intersect B & C, so you can not stop early.
Is there a way for us to quicken the computations by creating algorithms that create smarter boxes or must it be done on a case by case basis?
I understand the example of sorting numbers in the previous slide, but what does it mean to sort triangles? Moreover, for BVH algorithm, do you always loop through all the triangles first and construct such a tree based on the sorting algorithm before you do anything else?
@siliangl The sorting is a metaphor for preprocessing the data / building an acceleration data structure to support certain repeated operations, in this case finding the first ray-triangle intersection.
To construct a BVH, you might not "loop through" all the triangles first in order; you might partition them or group them first before getting to the leaf nodes. BVH construction doesn't explicitly use a "sorting" algorithm as in the previous slide, which was again just a metaphor.