The solution briefly mentioned in class is to create polygons for 'holes' on the surface, and tag them to indicate they are not part of the represented surface. This way we avoid any special cases.
echo
If it's a huge mesh with many polygons and I'd like to go over all polygons within a certain distance from a center vertex the method is that I first find all neighboring vertexes and for each one repeat the same method again. Seems that each polygon is visited many times...Is there a better method for this halfedge structure?
keenan
@ChrisZzh Yes, @zyx has it right: a very elegant way to treat surfaces with boundary is to add an additional polygon for each component of the boundary (as well as a cycle of halfedges around this polygon), and tag this polygon with a flag that specifies BOUNDARY/NOT BOUNDARY. This way, the code for mesh traversal (e.g., looping around a vertex) can be uniform and does not have to check for special cases. Of course, one still needs to check this flag when performing certain computations: for instance, if I want the sum of the areas of all polygons containing a given vertex, I shouldn't add the area of the boundary polygon!
You could also imagine other solutions: for instance, you could set the twin of any boundary halfedge to null, and check for null when traversing the mesh. But this makes it more difficult (for instance) to circulate around a vertex.
keenan
@echo Yes. Actually, you've rolled two nice questions into one:
1) How do I avoid redundantly iterating over elements I've already visited?
2) How do I efficiently perform queries based on geometric criteria (e.g., proximity in space) rather than topological criteria (e.g., connected by a path of k edges).
The first question comes up a lot not only when traversing a half edge mesh, but really when iterating over any topological data structure---even a simple graph. For instance, how would you implement depth-first search on a graph? Starting at a given node, you would start pushing neighbors onto a stack, and popping them off to get the next node in the traversal. To avoid pushing nodes you've already visited, you could simply maintain a flag VISITED/NOT VISITED. Same story for doing complex traversals on a half edge mesh: if you're worried about doing redundant computation, you can always flag mesh elements as "already visited." To make this even more efficient (e.g., if you need to iterate over the same complicated neighborhood many times) you could always cache a list of the elements you'll visit in a fixed list---at the cost of additional memory storage. And so on.
The second question is something we'll talk about two lectures from now: how do I find, say, points that are close in space, rather than points that are a short walk away on the mesh? These two can be very different: consider for instance a towel that's been folded many times over. The distance between two points on different "layers" of the towel will be very different depending on whether you travel along the towel, or through free space. The data structures we've discussed so far are not designed for finding points that are close in space; for that we'll need spatial acceleration data structures like bounding volume hierarchies, kd-trees, etc. (This discussion will also naturally lead into our discussion of ray tracing, where fast geometric queries are critical.)
theyComeAndGo
If the shape is not manifold, say it violates the fan condition, can't we just store a list of fans?
keenan
@theyComeAndGo Sure, you could do this; of course, now you have to think about how to traverse this list for different types of neighborhood queries, and how to maintain it when the mesh changes. In general the question is not "can I do this" but "is it worth the additional complexity?"
tcl1
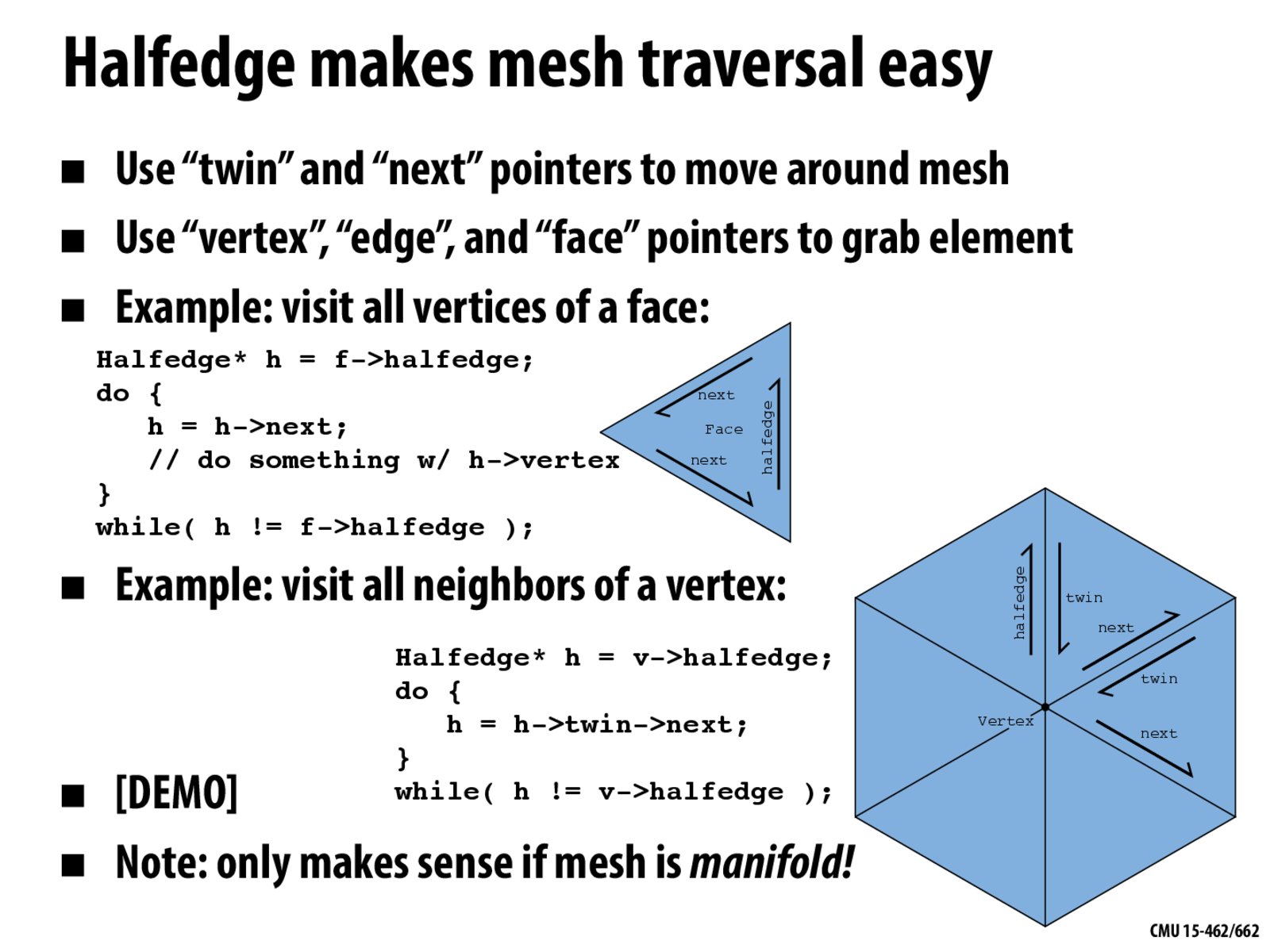
So in order to get the previous half edge, you would have to go all the way around till the next halfedge is the one you're starting from?
What is the twin of a half edge on a boundary?
The solution briefly mentioned in class is to create polygons for 'holes' on the surface, and tag them to indicate they are not part of the represented surface. This way we avoid any special cases.
If it's a huge mesh with many polygons and I'd like to go over all polygons within a certain distance from a center vertex the method is that I first find all neighboring vertexes and for each one repeat the same method again. Seems that each polygon is visited many times...Is there a better method for this halfedge structure?
@ChrisZzh Yes, @zyx has it right: a very elegant way to treat surfaces with boundary is to add an additional polygon for each component of the boundary (as well as a cycle of halfedges around this polygon), and tag this polygon with a flag that specifies BOUNDARY/NOT BOUNDARY. This way, the code for mesh traversal (e.g., looping around a vertex) can be uniform and does not have to check for special cases. Of course, one still needs to check this flag when performing certain computations: for instance, if I want the sum of the areas of all polygons containing a given vertex, I shouldn't add the area of the boundary polygon!
You could also imagine other solutions: for instance, you could set the twin of any boundary halfedge to null, and check for null when traversing the mesh. But this makes it more difficult (for instance) to circulate around a vertex.
@echo Yes. Actually, you've rolled two nice questions into one:
1) How do I avoid redundantly iterating over elements I've already visited?
2) How do I efficiently perform queries based on geometric criteria (e.g., proximity in space) rather than topological criteria (e.g., connected by a path of k edges).
The first question comes up a lot not only when traversing a half edge mesh, but really when iterating over any topological data structure---even a simple graph. For instance, how would you implement depth-first search on a graph? Starting at a given node, you would start pushing neighbors onto a stack, and popping them off to get the next node in the traversal. To avoid pushing nodes you've already visited, you could simply maintain a flag VISITED/NOT VISITED. Same story for doing complex traversals on a half edge mesh: if you're worried about doing redundant computation, you can always flag mesh elements as "already visited." To make this even more efficient (e.g., if you need to iterate over the same complicated neighborhood many times) you could always cache a list of the elements you'll visit in a fixed list---at the cost of additional memory storage. And so on.
The second question is something we'll talk about two lectures from now: how do I find, say, points that are close in space, rather than points that are a short walk away on the mesh? These two can be very different: consider for instance a towel that's been folded many times over. The distance between two points on different "layers" of the towel will be very different depending on whether you travel along the towel, or through free space. The data structures we've discussed so far are not designed for finding points that are close in space; for that we'll need spatial acceleration data structures like bounding volume hierarchies, kd-trees, etc. (This discussion will also naturally lead into our discussion of ray tracing, where fast geometric queries are critical.)
If the shape is not manifold, say it violates the fan condition, can't we just store a list of fans?
@theyComeAndGo Sure, you could do this; of course, now you have to think about how to traverse this list for different types of neighborhood queries, and how to maintain it when the mesh changes. In general the question is not "can I do this" but "is it worth the additional complexity?"
So in order to get the previous half edge, you would have to go all the way around till the next halfedge is the one you're starting from?