I noticed the explanation of inner product a little confusing. Two vectors with very big magnitude could have large dot even if the angle between is large. While two small vectors have limited inner product even if they are the same. So magnitude has obvious influence on the inner product, perhaps mention the formula cos<u,v> = u·v/(|u||v|)?
silentQ
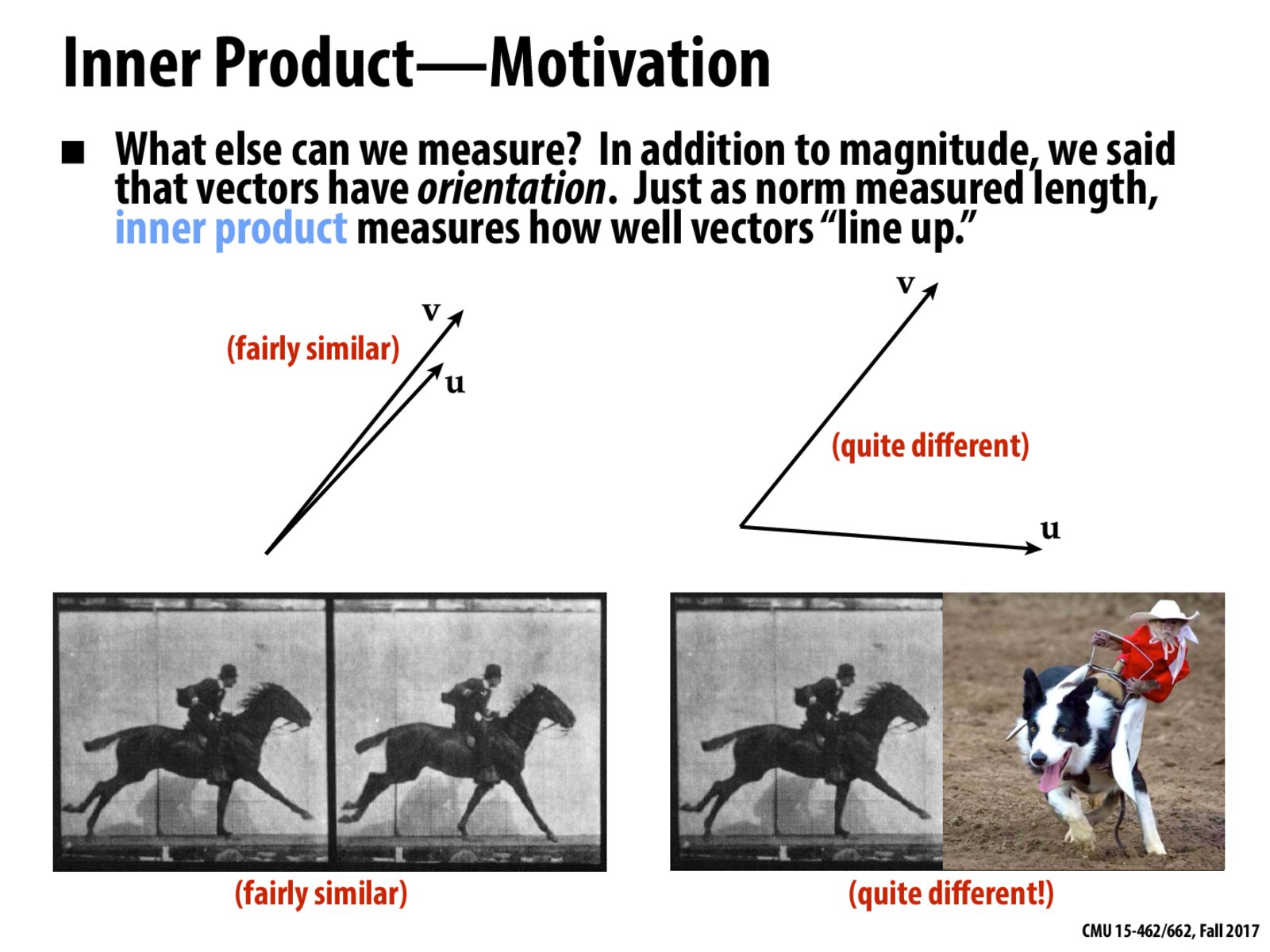
I think it's interesting the different ways "similarity" between images could be interpreted. If you take a photo and recolor only a few pixels, it makes sense that this would be considered very similar to the original, and I think most inner products would indicate this. But what if you took a photo and shifted it right a few dozen pixels? To a human, this would also look very similar to the original, but (depending on how it is stored and how detailed the image is) its inner product could be quite small because each pixel has changed quite a bit. Are there different kinds of inner products out there that would accommodate these different interpretations of "similarity"?
keenan
@echo Yes, that’s a very important point: the inner product of two unit vectors measures how well aligned they are (just the cosine of the angle between them). In general, it will also grow in proportion to the magnitude of the vectors (<u,v> = |u||v|cos(theta)). To get a rough sense of similarity between images, it may perhaps make sense to normalize them by their total magnitude and then take an inner product (for instance). Of course, you could also just take the norm of their difference! (What’s the relationship between these two measurements?)
keenan
@silentQ Yes, absolutely: you’d very much like the measure of similarity to be invariant to natural transformations such as translation and perhaps even scaling. Now we’re getting into the realm of image descriptors, which are widely used in computer vision. Interestingly enough, many basic deep learning systems will break down if you train them on a certain data set, and then apply them to data with seemingly superficial transformations (like translations, or changes in brightness). In geometry processing, there’s an ongoing quest to find good ways to measure the difference between two 3D shapes. So, the question you ask is far from superficial!
I noticed the explanation of inner product a little confusing. Two vectors with very big magnitude could have large dot even if the angle between is large. While two small vectors have limited inner product even if they are the same. So magnitude has obvious influence on the inner product, perhaps mention the formula cos<u,v> = u·v/(|u||v|)?
I think it's interesting the different ways "similarity" between images could be interpreted. If you take a photo and recolor only a few pixels, it makes sense that this would be considered very similar to the original, and I think most inner products would indicate this. But what if you took a photo and shifted it right a few dozen pixels? To a human, this would also look very similar to the original, but (depending on how it is stored and how detailed the image is) its inner product could be quite small because each pixel has changed quite a bit. Are there different kinds of inner products out there that would accommodate these different interpretations of "similarity"?
@echo Yes, that’s a very important point: the inner product of two unit vectors measures how well aligned they are (just the cosine of the angle between them). In general, it will also grow in proportion to the magnitude of the vectors (<u,v> = |u||v|cos(theta)). To get a rough sense of similarity between images, it may perhaps make sense to normalize them by their total magnitude and then take an inner product (for instance). Of course, you could also just take the norm of their difference! (What’s the relationship between these two measurements?)
@silentQ Yes, absolutely: you’d very much like the measure of similarity to be invariant to natural transformations such as translation and perhaps even scaling. Now we’re getting into the realm of image descriptors, which are widely used in computer vision. Interestingly enough, many basic deep learning systems will break down if you train them on a certain data set, and then apply them to data with seemingly superficial transformations (like translations, or changes in brightness). In geometry processing, there’s an ongoing quest to find good ways to measure the difference between two 3D shapes. So, the question you ask is far from superficial!