How is the best possible rule for the job chosen (for example, quads v.s. triangles v.s. other shapes)?
kc1
What is a good rule of thumb for how fine to make meshes?
keenan
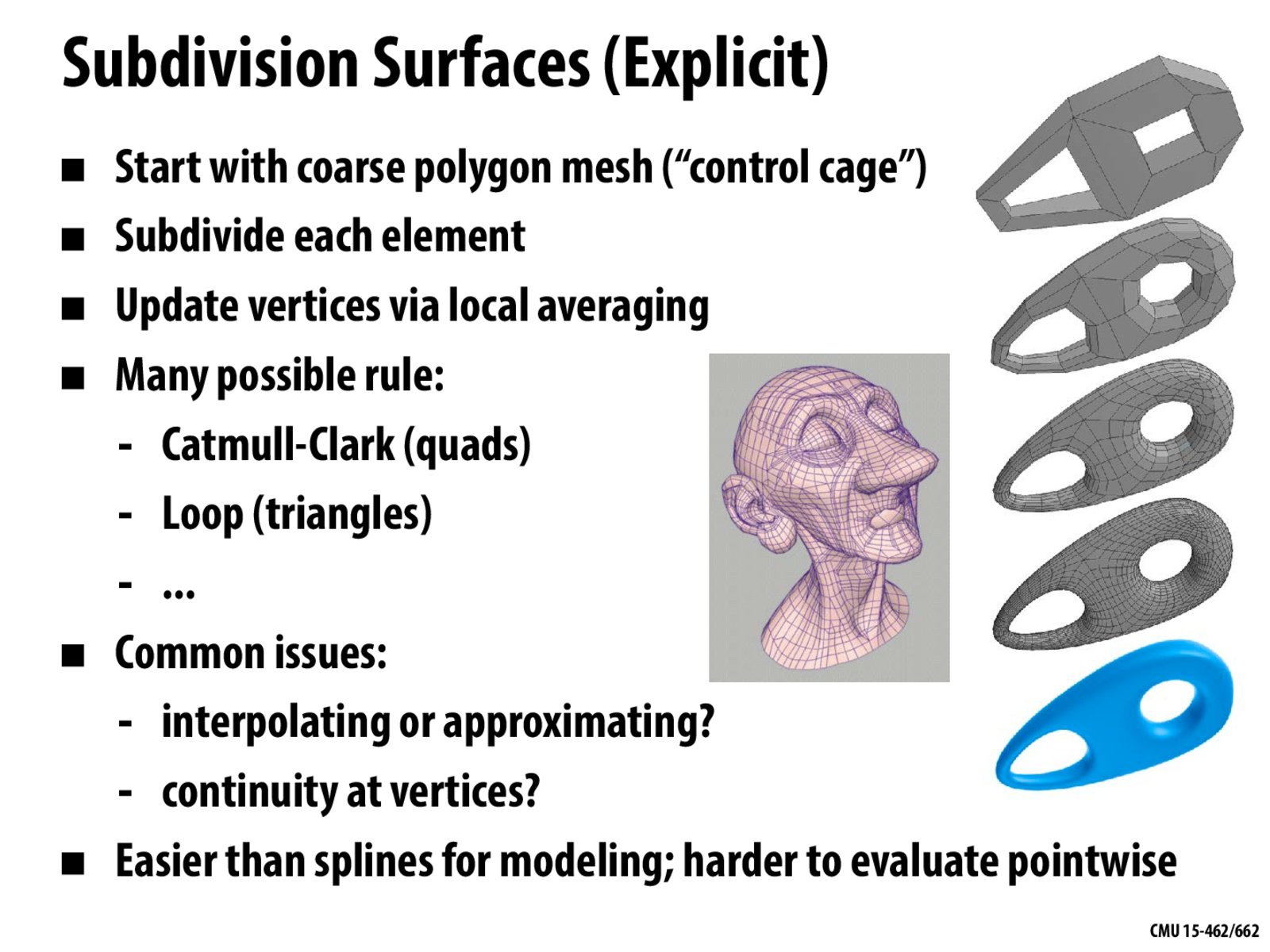
@mzeitlin Usually you don't get to choose triangles vs. quads; someone hands you a mesh and you have to subdivide it. There are rules that work well for quad-dominant meshes (like Catmull-Clark), and rules that work well for triangle-dominant meshes (like Loop). However, there are other schemes that might provide different trade offs; for instance, among triangle subdivision schemes there's Loop, Butterfly, Sqrt(3), ... Each of these has different properties, e.g., does it interpolate the control points, what's the degree of smoothness at irregular vertices, how much bigger does the mesh get after each subdivision, etc. If you're really interested in this subject, there are some great course notes.
keenan
@kc1 The basic guiding principle is what we discussed when talking about rasterization: you want to sample the geometry at a sufficiently fine rate to ensure that you're accurately capturing all the features of interest. A rough rule of thumb is Shannon's sampling theorem. When you have both geometry and rendering in the mix, things get a lot trickier: you ultimately want to make sure that the illumination is sampled at a sufficiently high rate, and the illumination calculations in turn depend on the frequency at which the geometry was sampled. In general these calculations do not depend solely on the distance of an object from the viewer: for instance, light scattered off a distant, extremely shiny object might bounce over to a wall near the viewer. In this case, you'd have to sample the geometry at a much higher rate than what you'd determine from its size in screen space (as we did for MIP mapping). So... it's hard! And computer graphics research continues to ask this kind of question (for instance, by considering how light behaves in the frequency domain). In classic, Pixar-style REYES rendering (as implemented in RenderMan) the strategy was to subdivide surfaces down until each triangle is smaller than a pixel (also called "micropolygon rendering"). But even this strategy doesn't directly address the example given above.
How is the best possible rule for the job chosen (for example, quads v.s. triangles v.s. other shapes)?
What is a good rule of thumb for how fine to make meshes?
@mzeitlin Usually you don't get to choose triangles vs. quads; someone hands you a mesh and you have to subdivide it. There are rules that work well for quad-dominant meshes (like Catmull-Clark), and rules that work well for triangle-dominant meshes (like Loop). However, there are other schemes that might provide different trade offs; for instance, among triangle subdivision schemes there's Loop, Butterfly, Sqrt(3), ... Each of these has different properties, e.g., does it interpolate the control points, what's the degree of smoothness at irregular vertices, how much bigger does the mesh get after each subdivision, etc. If you're really interested in this subject, there are some great course notes.
@kc1 The basic guiding principle is what we discussed when talking about rasterization: you want to sample the geometry at a sufficiently fine rate to ensure that you're accurately capturing all the features of interest. A rough rule of thumb is Shannon's sampling theorem. When you have both geometry and rendering in the mix, things get a lot trickier: you ultimately want to make sure that the illumination is sampled at a sufficiently high rate, and the illumination calculations in turn depend on the frequency at which the geometry was sampled. In general these calculations do not depend solely on the distance of an object from the viewer: for instance, light scattered off a distant, extremely shiny object might bounce over to a wall near the viewer. In this case, you'd have to sample the geometry at a much higher rate than what you'd determine from its size in screen space (as we did for MIP mapping). So... it's hard! And computer graphics research continues to ask this kind of question (for instance, by considering how light behaves in the frequency domain). In classic, Pixar-style REYES rendering (as implemented in RenderMan) the strategy was to subdivide surfaces down until each triangle is smaller than a pixel (also called "micropolygon rendering"). But even this strategy doesn't directly address the example given above.