As we translate an 3D object into a 2D image (or 3D points to 2D), we lose the information of depth, which is useful in deciding which edge or face is on top of another. For example, when we draw this cube, the vertex A should have been blocked by face(G, H, F, E). With the method described in class, we can only draw the edges without determining which edge/ vertex should not be displayed. In practice, how do we solve this? Do we solve this prior to translating models into 2D or do we preserve the "depth information" during transformation and later utilize it to determine blocking?
abiagioli
@hanliny Generally, we of course do not want to draw objects via only their edges (although you can in any graphics API like OpenGL). The norm is to draw triangles instead (we will go over this soon!). One solution to support depth is to render triangles back-to-front based on their centroids. This sort of works, but breaks in many situations (ex: intersecting triangles). To solve this most games use some sort of depth buffer that encodes the closest thing rendered for each pixel. This is a single-channel texture that is rendered in addition to the primary framebuffer (that is pushed to your monitor). See below for an example:
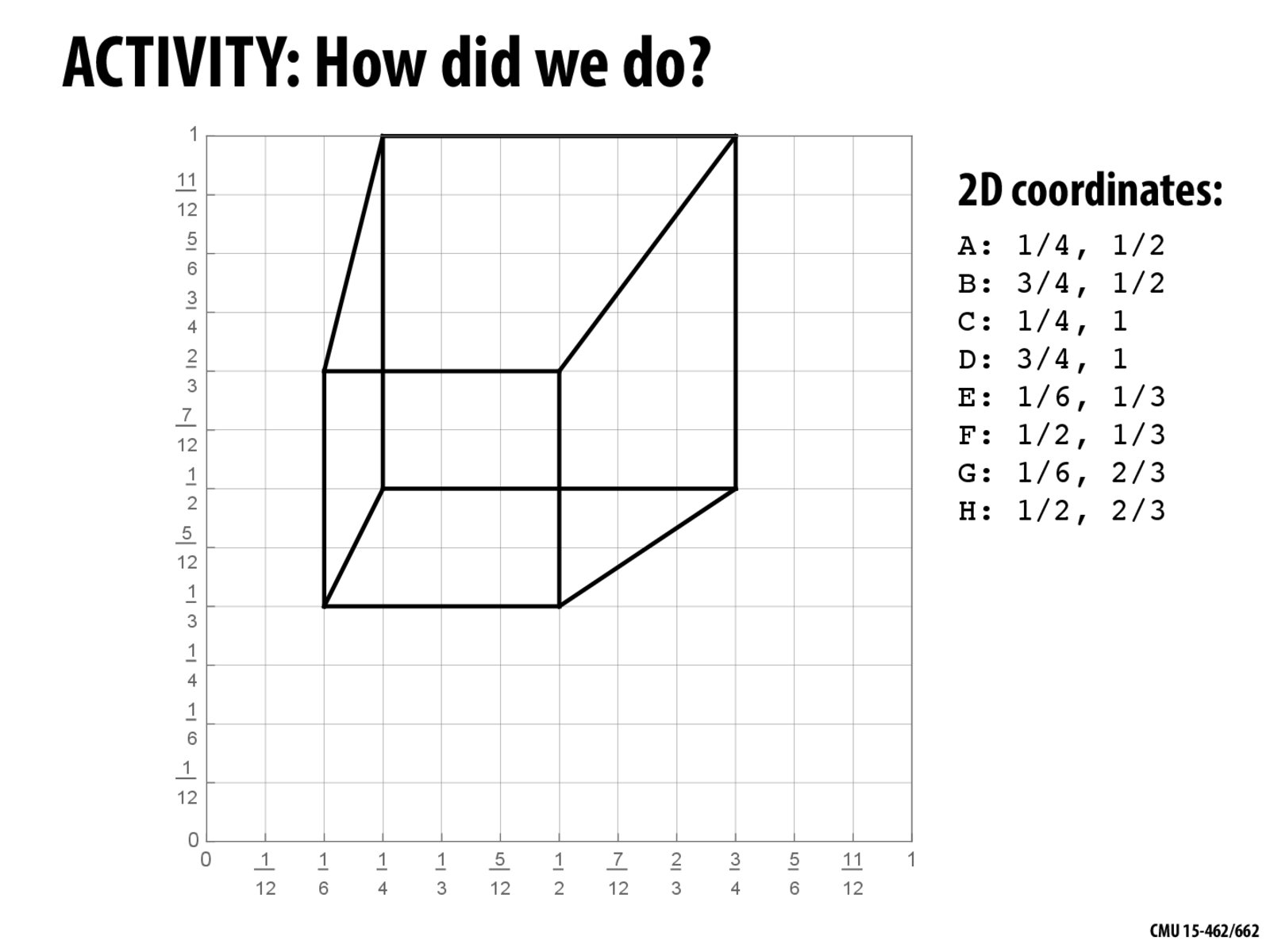
As we translate an 3D object into a 2D image (or 3D points to 2D), we lose the information of depth, which is useful in deciding which edge or face is on top of another. For example, when we draw this cube, the vertex A should have been blocked by face(G, H, F, E). With the method described in class, we can only draw the edges without determining which edge/ vertex should not be displayed. In practice, how do we solve this? Do we solve this prior to translating models into 2D or do we preserve the "depth information" during transformation and later utilize it to determine blocking?
@hanliny Generally, we of course do not want to draw objects via only their edges (although you can in any graphics API like OpenGL). The norm is to draw triangles instead (we will go over this soon!). One solution to support depth is to render triangles back-to-front based on their centroids. This sort of works, but breaks in many situations (ex: intersecting triangles). To solve this most games use some sort of depth buffer that encodes the closest thing rendered for each pixel. This is a single-channel texture that is rendered in addition to the primary framebuffer (that is pushed to your monitor). See below for an example: