A few lectures ago we saw basically the same slide where Kayvon mentioned that the number of buckets is typically < 32. One reason I can think of for why 32 would be a good number for the number of buckets is that CUDA warps have 32 threads. All 32 threads in a warp execute concurrently.
So one way to parallelize this task is to
1) assign a group of primitives to each CUDA thread to figure out which bucket it maps to
2) once you have this info you can assign each thread to a bucket and have each thread compute the bounding box for a bucket as well as the bucket's prim count concurrently
3) Do a sync across the threads
4) Then have each thread compute the SAH of the partition that splits right at the end of its buckets range (note that one thread will not have anything to at this step because if there are 32 buckets there are only 31 splitting planes).
One thing to be concerned about is that there may be very uneven work distribution across threads in a warp if primitive in a node are all clustered in one area, i.e. mostly map to a few buckets.
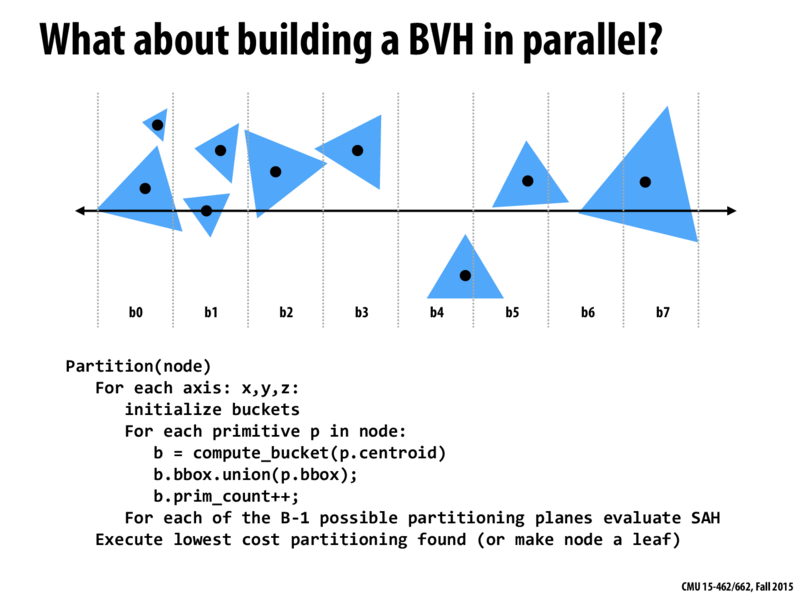
A few lectures ago we saw basically the same slide where Kayvon mentioned that the number of buckets is typically < 32. One reason I can think of for why 32 would be a good number for the number of buckets is that CUDA warps have 32 threads. All 32 threads in a warp execute concurrently.
So one way to parallelize this task is to
1) assign a group of primitives to each CUDA thread to figure out which bucket it maps to
2) once you have this info you can assign each thread to a bucket and have each thread compute the bounding box for a bucket as well as the bucket's prim count concurrently
3) Do a sync across the threads
4) Then have each thread compute the SAH of the partition that splits right at the end of its buckets range (note that one thread will not have anything to at this step because if there are 32 buckets there are only 31 splitting planes).
One thing to be concerned about is that there may be very uneven work distribution across threads in a warp if primitive in a node are all clustered in one area, i.e. mostly map to a few buckets.