I find it a bit confusing that we can map the frustrum, which looks like a skewed cube, to a normal unit cube without distorting any objects in view. Possibly related: how would you actually calculate (for example) r-l, when the frustrum is wider in the back than it is in the front?
mangopi
What kind of hardware supports this/ how is the architecture for that hardware specifically tailored for clipping?
WhaleVomit
Same question as gloose. How come this mapping from the frustum to the cube doesn't distort the objects?
Also, how would a perspective projection be different?
jcm
Do we change the view frustum based on the size of the screen?
Marco
Is this the same idea of using homogeneous coordinates to represent 2D translation as a 3D shear? Except that now a 3D translation becomes a 4D shear?
corgo
Why doesn't this mapping distort the objects?
Mogician
Why this transform has to be linear? Just out of the convenience?
abigalekim
Extending/application of the mapping problem, if we wanted to implement, say a person's nearsightedness or farsightedness, would we just translate the frustum?
air54321
Why do we map y into a 4-tuple and, consequently, create a 4x4 matrix? What is the 4th element representing here?
Coyote
The illustration makes the cube seem distorted. Though I'm sure it looks fine as is, if we were to change the FOV would that affect how the cube is seen (make it distorted, or something else)?
anj
This mapping scales and translates, but would it not change the way an object is viewed from these two projections?
kurt
Will this step distort the item?
Bellala
How do we decide the znear and zfar?
Concurrensee
Is there way to compute in complex domain?
urae
What is the purpose of the 4th column in the matrix?
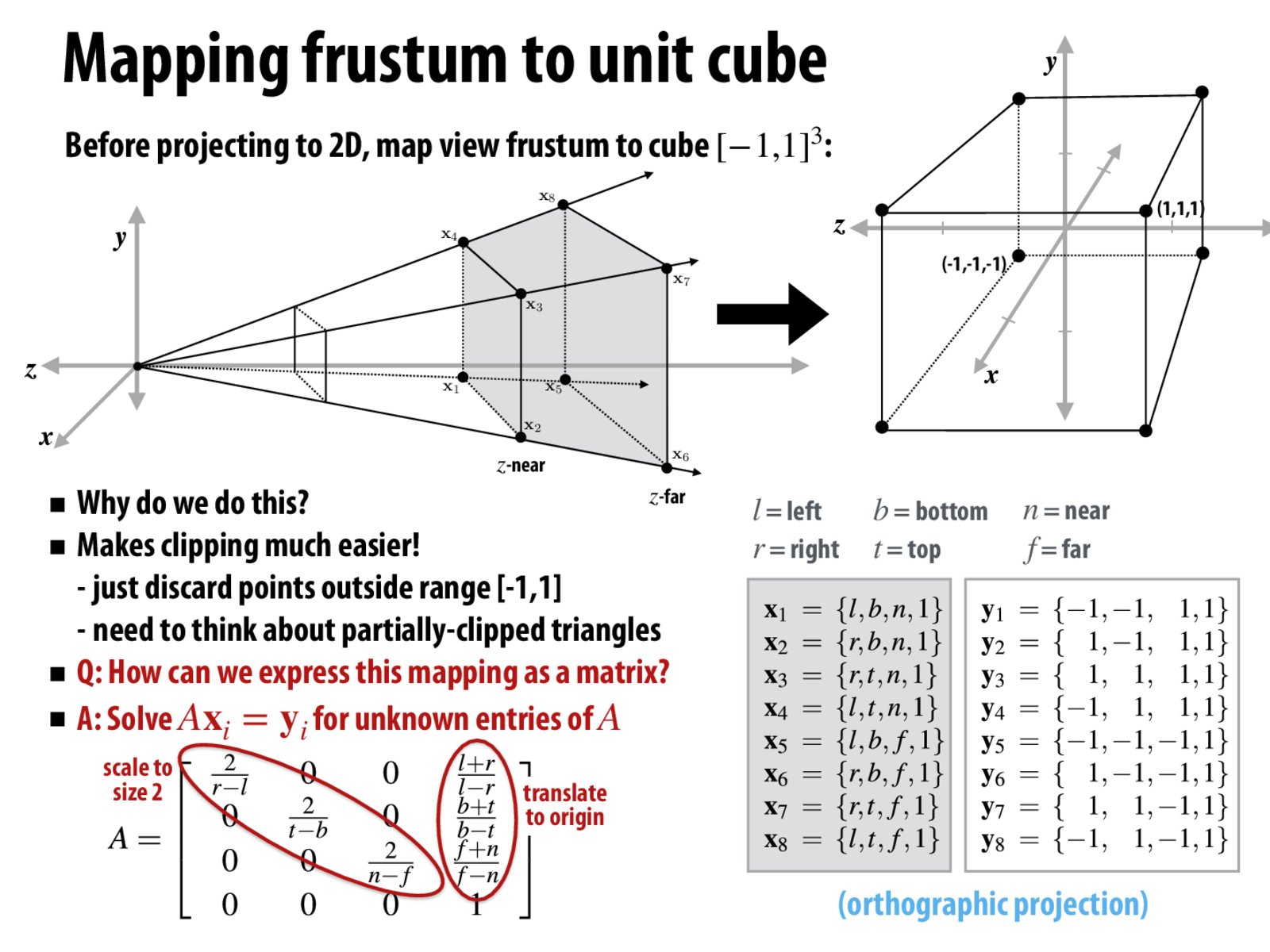
I find it a bit confusing that we can map the frustrum, which looks like a skewed cube, to a normal unit cube without distorting any objects in view. Possibly related: how would you actually calculate (for example) r-l, when the frustrum is wider in the back than it is in the front?
What kind of hardware supports this/ how is the architecture for that hardware specifically tailored for clipping?
Same question as gloose. How come this mapping from the frustum to the cube doesn't distort the objects?
Also, how would a perspective projection be different?
Do we change the view frustum based on the size of the screen?
Is this the same idea of using homogeneous coordinates to represent 2D translation as a 3D shear? Except that now a 3D translation becomes a 4D shear?
Why doesn't this mapping distort the objects?
Why this transform has to be linear? Just out of the convenience?
Extending/application of the mapping problem, if we wanted to implement, say a person's nearsightedness or farsightedness, would we just translate the frustum?
Why do we map y into a 4-tuple and, consequently, create a 4x4 matrix? What is the 4th element representing here?
The illustration makes the cube seem distorted. Though I'm sure it looks fine as is, if we were to change the FOV would that affect how the cube is seen (make it distorted, or something else)?
This mapping scales and translates, but would it not change the way an object is viewed from these two projections?
Will this step distort the item?
How do we decide the znear and zfar?
Is there way to compute in complex domain?
What is the purpose of the 4th column in the matrix?