Why do we go through the trouble of moving the z value to the fourth coordinate only to drop the z value and then divide the x and y value by the fourth coordinate? Why not just directly do the homogenous divide using the z value?
kayvonf
@lucida. Although not discussed in this lecture, we need the Z-coordinate (after some normalization) for depth testing. See the canonical view volume illustration in the next lecture for more on how the Z value is scaled in practice. The goal is to make depths in the camera-space view frustum lie in the -1 to +1 z range after applying the perspective projection transformation and applying the homogeneous divide. The result is a normalized Z value per vertex. This value is interpolated (like all other attributes) to get a per sample Z for depth testing.
ak-47
I don't understand what the P matrix is here...is the last row supposed to represent the camera direction? Are the top three rows always a 3x3 Identity matrix?
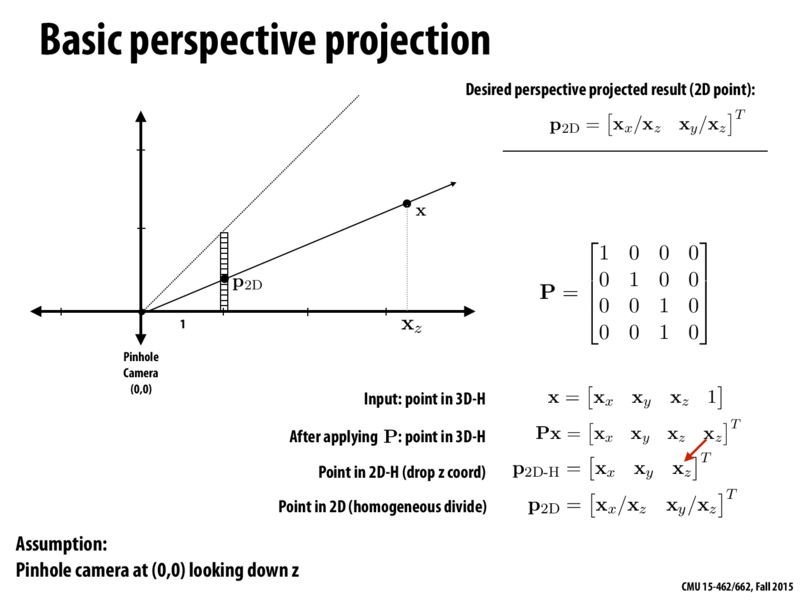
Why do we go through the trouble of moving the z value to the fourth coordinate only to drop the z value and then divide the x and y value by the fourth coordinate? Why not just directly do the homogenous divide using the z value?
@lucida. Although not discussed in this lecture, we need the Z-coordinate (after some normalization) for depth testing. See the canonical view volume illustration in the next lecture for more on how the Z value is scaled in practice. The goal is to make depths in the camera-space view frustum lie in the -1 to +1 z range after applying the perspective projection transformation and applying the homogeneous divide. The result is a normalized Z value per vertex. This value is interpolated (like all other attributes) to get a per sample Z for depth testing.
I don't understand what the P matrix is here...is the last row supposed to represent the camera direction? Are the top three rows always a 3x3 Identity matrix?