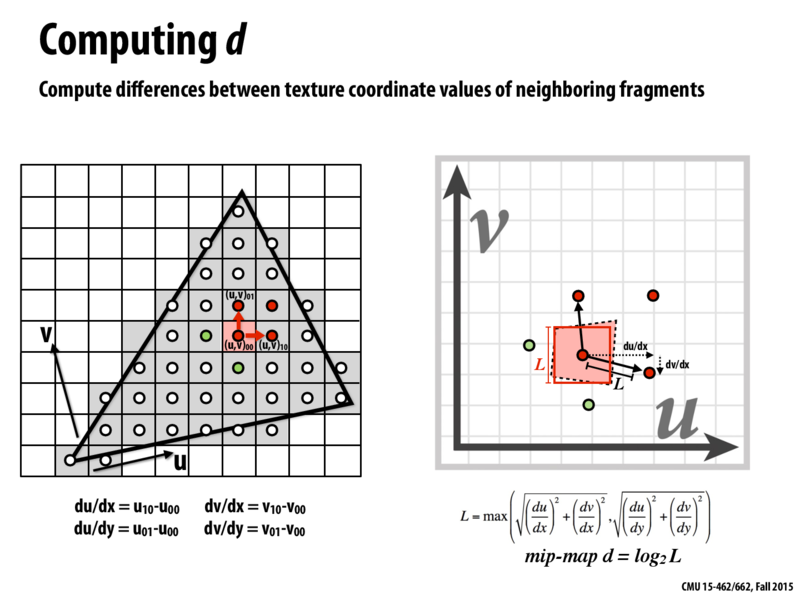
My intuition for why we take the log of L is that since we can't have an infinite number of mip-maps, just like how floating points are designed to have more accuracy near zero, given a limited number of mip-maps, we choose to generate more mip-maps for the range of depths closest to the viewer.
This means given a small change in depth for a surface that is relatively close to the viewer (i.e. when L has a small value because the distance between points in texture space is small when we are zoomed in), the renderer will likely switch to a different (higher) level d mip-map, because L has increased and for small values of L, small increases in L are enough for log(L) to reach the next integer d mip-map.
However, given this same change in depth for a surface that is relatively far from the viewer, the renderer will probably still use the same level mip-map because when objects are far away, the distance between points in texture space is large, i.e. L is now large and so we need a large change in L to reach the next integer value of log(L).
In short, we allocate our memory resources to provide better accuracy for closer surfaces.
BryceSummers
@lucida It is also worth noting that because of perspective projection, the farther away from the viewer we get, the farther further we would have to go to make a significant change in the viewer's perception of us.
This is because screen_x ~= real_x/distance_to_viewer and screen_y ~= real_y / distance_to_viewer.
The changes are much more dramatic when they are closer.
We also use base 2, because neighbor mipmaps are related by a ratio of 4 cause by halving each dimension. Doing so makes it easier to sample and compute the mipmaps, because they can be calculated from integral sample space locations on the larger mipmap without interpolation.
My intuition for why we take the log of L is that since we can't have an infinite number of mip-maps, just like how floating points are designed to have more accuracy near zero, given a limited number of mip-maps, we choose to generate more mip-maps for the range of depths closest to the viewer.
This means given a small change in depth for a surface that is relatively close to the viewer (i.e. when L has a small value because the distance between points in texture space is small when we are zoomed in), the renderer will likely switch to a different (higher) level d mip-map, because L has increased and for small values of L, small increases in L are enough for log(L) to reach the next integer d mip-map.
However, given this same change in depth for a surface that is relatively far from the viewer, the renderer will probably still use the same level mip-map because when objects are far away, the distance between points in texture space is large, i.e. L is now large and so we need a large change in L to reach the next integer value of log(L).
In short, we allocate our memory resources to provide better accuracy for closer surfaces.
@lucida It is also worth noting that because of perspective projection, the farther away from the viewer we get, the farther further we would have to go to make a significant change in the viewer's perception of us.
This is because screen_x ~= real_x/distance_to_viewer and screen_y ~= real_y / distance_to_viewer.
The changes are much more dramatic when they are closer.
We also use base 2, because neighbor mipmaps are related by a ratio of 4 cause by halving each dimension. Doing so makes it easier to sample and compute the mipmaps, because they can be calculated from integral sample space locations on the larger mipmap without interpolation.