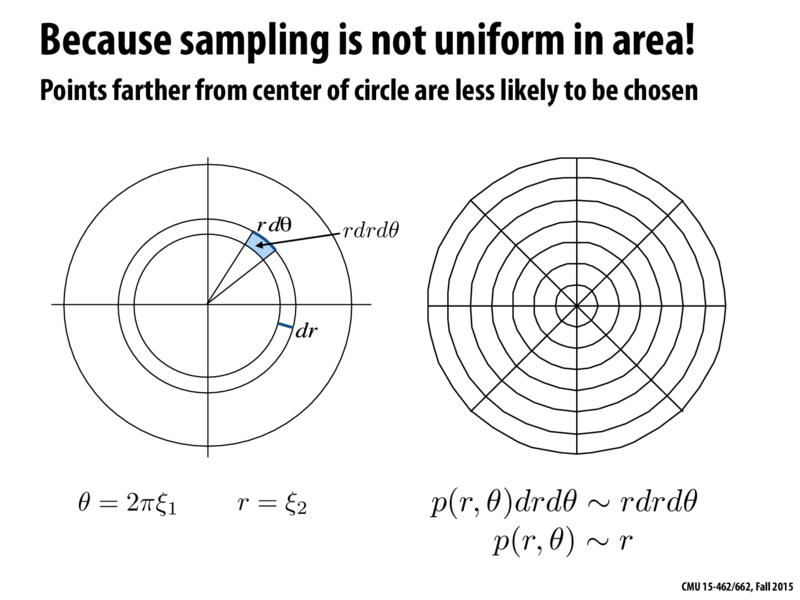
I'm not really following what's going on in this slide. why is $p(r, \theta) \approx r$? If anything wouldn't it be $(1 / r) \cdot (1 / \theta)$ because $r$ and $\theta$ are chosen independently from each other and uniformly amongst their distributions?
BryceSummers
Let R be the radius of the circle we are sampling from. (Constant)
Let r be a fixed and arbitrary target radius.
Let $\theta$ be a fixed and arbitrary target angle.
$p(r, \theta) = p(r) * p(\theta)$
$ = (1/R) * p(\theta)$
$ = (1/R) * 1/(2pir)$
$= (1/(R2pi)) * (1/r)$
For direct proportionality, we can eliminate the constant terms.
$p(r, \theta) \approx (1/r)$
mchoquet
@dvernet: let me given an alternative explanation: we want $p(r) \sim r$ (not $\approx$, $\sim$ means "proportional to"), so the probability of our sample being at some radius $r$ increases linearly as that radius increases. This is reasonable because the amount of circle to sample points from at radius r increases linearly with r.
mchoquet
@doodooloo: the points everywhere in the circle should be equally likely to be chosen; having p(r) scale linearly with r achieves that effect.
BryceSummers
@doodooloo
A naive method will indeed lead to there being more density in the center.
Image
A correct uniform method like those on the slides after this one will have equal density everywhere.
kayvonf
I updated the slide title to make it more clear. I also fixed the subtitle to say: "points farther from the center are less likely to be chosen." thanks everyone.
dvernet
@kayvonf FYI it doesn't like your update took effect.
I'm not really following what's going on in this slide. why is $p(r, \theta) \approx r$? If anything wouldn't it be $(1 / r) \cdot (1 / \theta)$ because $r$ and $\theta$ are chosen independently from each other and uniformly amongst their distributions?
Let R be the radius of the circle we are sampling from. (Constant) Let r be a fixed and arbitrary target radius. Let $\theta$ be a fixed and arbitrary target angle.
$p(r, \theta) = p(r) * p(\theta)$
$ = (1/R) * p(\theta)$
$ = (1/R) * 1/(2pir)$
$= (1/(R2pi)) * (1/r)$
For direct proportionality, we can eliminate the constant terms.
$p(r, \theta) \approx (1/r)$
@dvernet: let me given an alternative explanation: we want $p(r) \sim r$ (not $\approx$, $\sim$ means "proportional to"), so the probability of our sample being at some radius $r$ increases linearly as that radius increases. This is reasonable because the amount of circle to sample points from at radius r increases linearly with r.
@doodooloo: the points everywhere in the circle should be equally likely to be chosen; having p(r) scale linearly with r achieves that effect.
@doodooloo
A naive method will indeed lead to there being more density in the center. Image
A correct uniform method like those on the slides after this one will have equal density everywhere.
I updated the slide title to make it more clear. I also fixed the subtitle to say: "points farther from the center are less likely to be chosen." thanks everyone.
@kayvonf FYI it doesn't like your update took effect.