I'm surprised that Metropolis Light Transport is unbiased given that it favors stepping towards regions that have more light. What's the reasoning here?
Sohil
I believe because we calculate the probabilities of following that particular markov chain very carefully, then the path we trace in MLT will be weighted by the probabilities of following that favorable path, and on average we expect the true integrand. I believe in MLT we only favor going towards paths with more light with some probability, so we can use that probability to weight our paths.
Edit: Also, I believe it has a lot to do with how we said our mutations are "ergodic", where if we can reach the entire sample space then by careful probability weighting we have a unbiased estimator.
kmcrane
@dvernet: The most important thing to keep in mind is that there is always some reasonable chance that you'll transition to a darker sample; we're not always going from dark to light. This basically has to be true in order for anything like Metropolis-Hastings to make sense: if we just accepted all transitions with, say, probability 1/2 (independent of the sample value), then our final collection of samples would look nothing like the integrand. That's why we have to go "uphill more" and "downhill less." (Of course, one must always prove that all of this converges... but that's the intuition.)
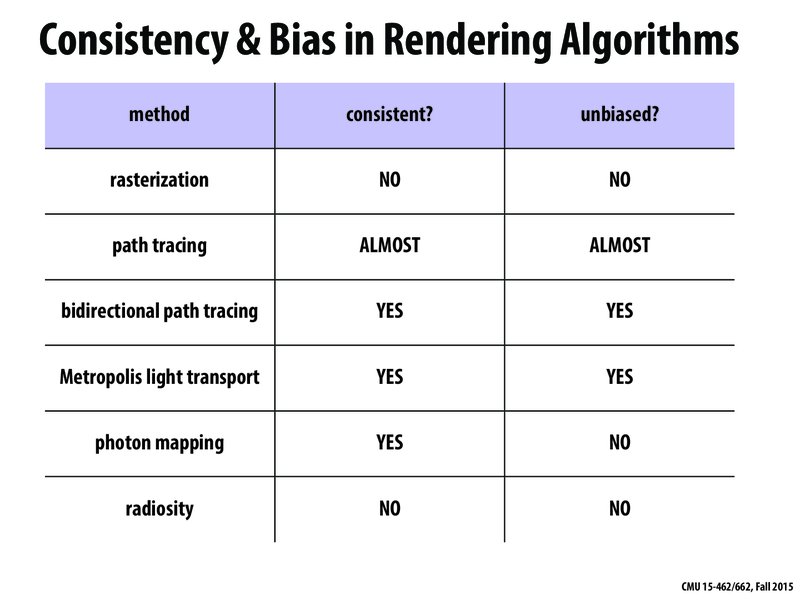
I'm surprised that Metropolis Light Transport is unbiased given that it favors stepping towards regions that have more light. What's the reasoning here?
I believe because we calculate the probabilities of following that particular markov chain very carefully, then the path we trace in MLT will be weighted by the probabilities of following that favorable path, and on average we expect the true integrand. I believe in MLT we only favor going towards paths with more light with some probability, so we can use that probability to weight our paths.
Edit: Also, I believe it has a lot to do with how we said our mutations are "ergodic", where if we can reach the entire sample space then by careful probability weighting we have a unbiased estimator.
@dvernet: The most important thing to keep in mind is that there is always some reasonable chance that you'll transition to a darker sample; we're not always going from dark to light. This basically has to be true in order for anything like Metropolis-Hastings to make sense: if we just accepted all transitions with, say, probability 1/2 (independent of the sample value), then our final collection of samples would look nothing like the integrand. That's why we have to go "uphill more" and "downhill less." (Of course, one must always prove that all of this converges... but that's the intuition.)