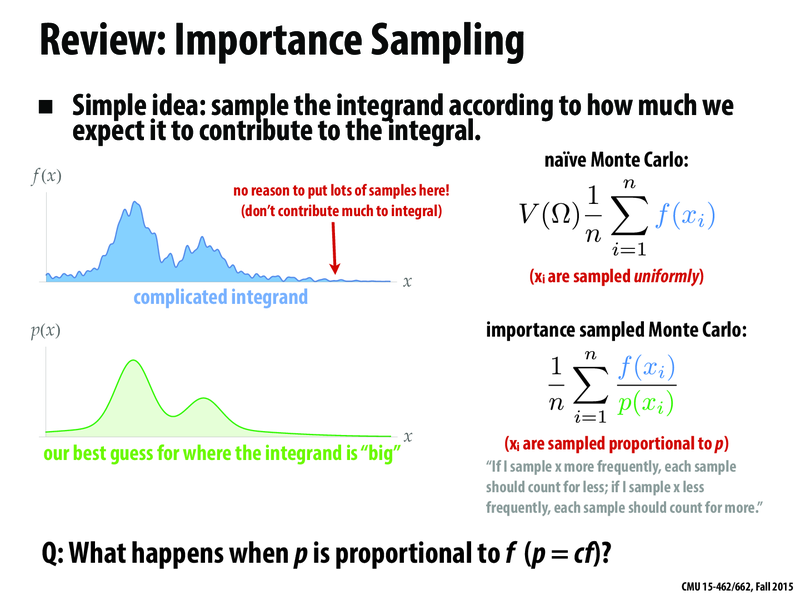
I don't understand the "If I sample $x$ more frequently, each sample should count for less; if I sample $x$ less frequently, each sample should count for more" motivation. I understand that we want to sample the signal near the mean because it gives us the most information, but I don't follow how dividing $f(x_{i})$ by $p(x_{i})$ would accomplish that.
WALL-E
Here shouldn't it be $f(x_i)*p(x_i)$. If $x_i$ has more probability than shouldn't $f(x_i)$ have more probability too..?
kmcrane
What's written on the slide is correct. For instance, suppose I'm integrating a function that is "half red" and "half blue," then the result should be purple. But if my importance density p says to sample 99% of the time in the red region (p=.99) and 1% of the time in the blue region (p=.01), then I'm going to end up with way more red samples than blue samples. Multiplying the red samples by .99 and the blue samples by .01 would make the result even more red. Therefore, I need to divide by p, so that each red sample just contributes a little to the total, and each blue sample contributes a lot.
PandaX
@kmcrane Thanks for the explanation.
But why do we need to multiplies it by the volume of the domain in importance sampling? The definition seems to be different in previous lecture's slide
Or is it just a typo?
kmcrane
@PandaX - Yes, it's a typo (arising from just copying the expression for the standard Monte Carlo estimator). Now fixed. In the case of a uniform distribution, $p = 1/V(\Omega)$, which means that $f/p = V(\Omega)f$.
dvernet
@kmcrane I'm still a bit confused by this slide. In your example you said that you're estimating a function that is half red and half blue, but that an importance density giving red 99% of the samples and blue 1% of the samples would cause it to render red. To fix this, we divide by the probability to even them out.
However, if you divide by the probability then aren't you implicitly making an assumption that your importance density is incorrect? In other words, if our distribution tells us to sample red 99% of the time and blue 1% of the time then why don't we just assume that it's because there should be 99x as much red as there is blue?
kmcrane
@dvernet: Because in that example I said that the function I'm integrating is half red and half blue. ;-) In other words, the importance density isn't picking the sample location based on color; it's picking it based on the location in the domain. So if half of the domain is red, and half of the domain is blue, but we have an importance sampling strategy that yields a very different distribution of samples, then we are doing something wrong!
I don't understand the "If I sample $x$ more frequently, each sample should count for less; if I sample $x$ less frequently, each sample should count for more" motivation. I understand that we want to sample the signal near the mean because it gives us the most information, but I don't follow how dividing $f(x_{i})$ by $p(x_{i})$ would accomplish that.
Here shouldn't it be $f(x_i)*p(x_i)$. If $x_i$ has more probability than shouldn't $f(x_i)$ have more probability too..?
What's written on the slide is correct. For instance, suppose I'm integrating a function that is "half red" and "half blue," then the result should be purple. But if my importance density p says to sample 99% of the time in the red region (p=.99) and 1% of the time in the blue region (p=.01), then I'm going to end up with way more red samples than blue samples. Multiplying the red samples by .99 and the blue samples by .01 would make the result even more red. Therefore, I need to divide by p, so that each red sample just contributes a little to the total, and each blue sample contributes a lot.
@kmcrane Thanks for the explanation.
But why do we need to multiplies it by the volume of the domain in importance sampling? The definition seems to be different in previous lecture's slide
Or is it just a typo?
@PandaX - Yes, it's a typo (arising from just copying the expression for the standard Monte Carlo estimator). Now fixed. In the case of a uniform distribution, $p = 1/V(\Omega)$, which means that $f/p = V(\Omega)f$.
@kmcrane I'm still a bit confused by this slide. In your example you said that you're estimating a function that is half red and half blue, but that an importance density giving red 99% of the samples and blue 1% of the samples would cause it to render red. To fix this, we divide by the probability to even them out.
However, if you divide by the probability then aren't you implicitly making an assumption that your importance density is incorrect? In other words, if our distribution tells us to sample red 99% of the time and blue 1% of the time then why don't we just assume that it's because there should be 99x as much red as there is blue?
@dvernet: Because in that example I said that the function I'm integrating is half red and half blue. ;-) In other words, the importance density isn't picking the sample location based on color; it's picking it based on the location in the domain. So if half of the domain is red, and half of the domain is blue, but we have an importance sampling strategy that yields a very different distribution of samples, then we are doing something wrong!