Could I get some further explanation on the third bullet point? I'm not sure why we need a matrix to copy the z coordinate into the homogeneous coordinate. Why can't we be satisfied with representing the 2D coordinate (e.g. (u,v) or (x/z,y/z)) as its homogeneous coordinate: (x/z, y/z)?
Thanks!
nsp
One of the goals of this process was to turn the perspective projection into a matrix operation that could be done as part of a long sequence of matrix ops that transform the geometry of your scene -- i.e., move them into position, put them in the camera's frame of view, do the projection. If we can create one single matrix to do all of that, then we form the matrix once and apply it (possibly in parallel) to a large number of triangles. The GPU is highly optimized to do all that.
Given our goal of making it a matrix operation in the first place, we need to copy z into the homogeneous coordinate because there is no way to do division through matrix multiplication. The division comes from the "trick" of dividing everything out by the homogeneous coordinate at the end of all the matrix operations.
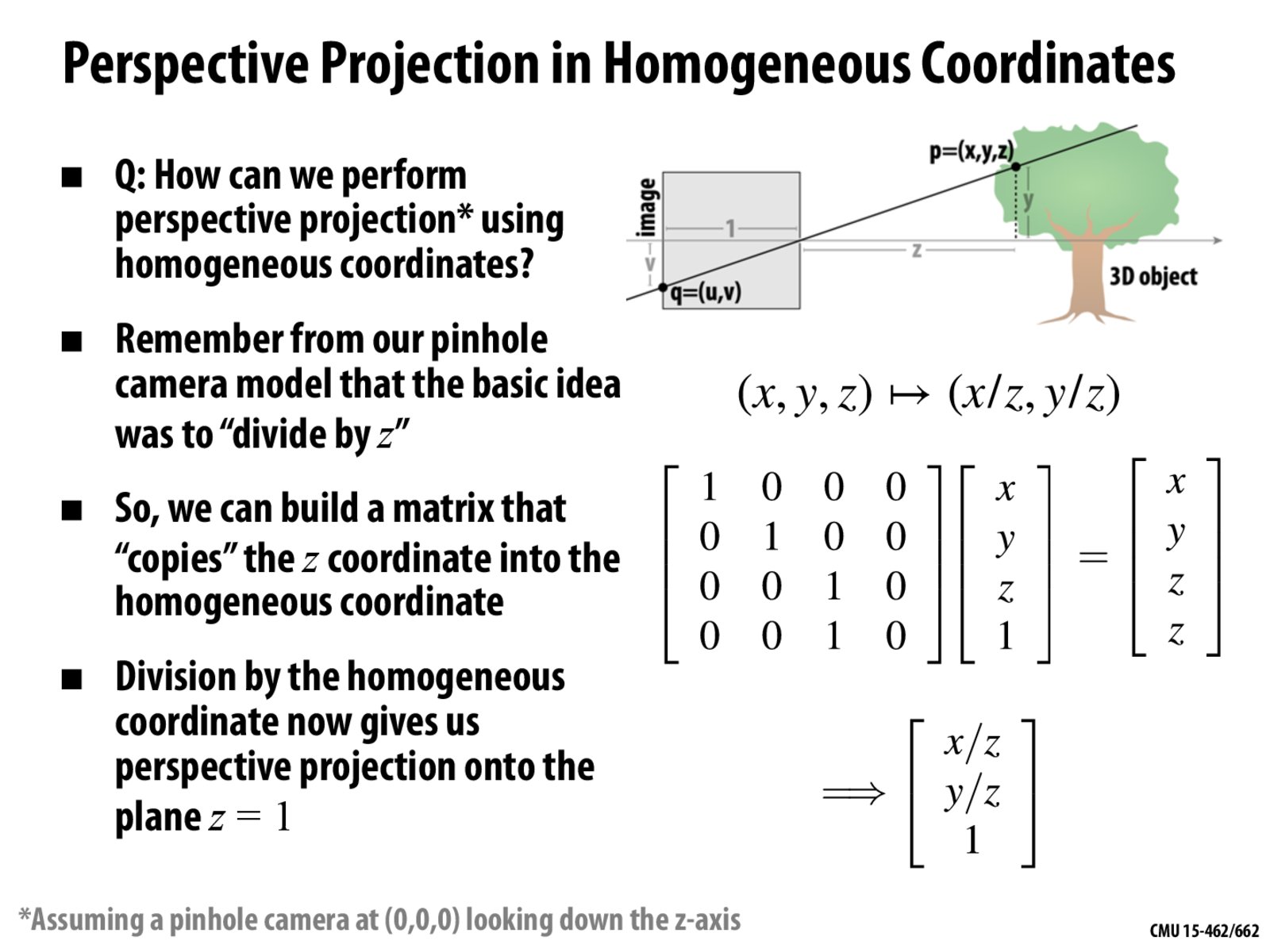
Could I get some further explanation on the third bullet point? I'm not sure why we need a matrix to copy the z coordinate into the homogeneous coordinate. Why can't we be satisfied with representing the 2D coordinate (e.g. (u,v) or (x/z,y/z)) as its homogeneous coordinate: (x/z, y/z)?
Thanks!
One of the goals of this process was to turn the perspective projection into a matrix operation that could be done as part of a long sequence of matrix ops that transform the geometry of your scene -- i.e., move them into position, put them in the camera's frame of view, do the projection. If we can create one single matrix to do all of that, then we form the matrix once and apply it (possibly in parallel) to a large number of triangles. The GPU is highly optimized to do all that.
Given our goal of making it a matrix operation in the first place, we need to copy z into the homogeneous coordinate because there is no way to do division through matrix multiplication. The division comes from the "trick" of dividing everything out by the homogeneous coordinate at the end of all the matrix operations.
Does that answer your question?