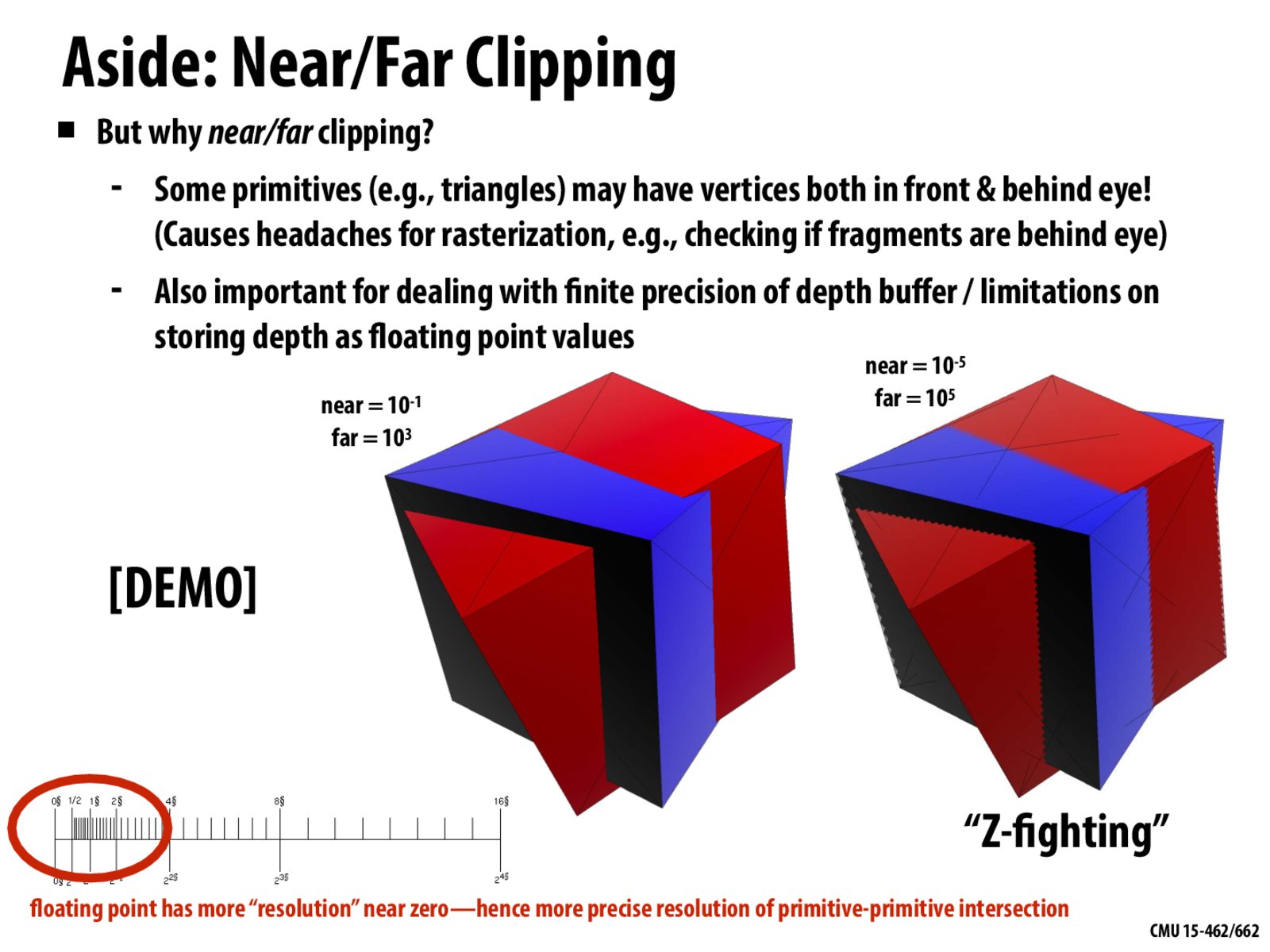
When professor was talking about this slide in today's lecture, he run some code and showed us a demo. Does anyone remember what the parameters that he adjusted while running the code mean? Why were there twinkling zig-zag patterns at the boundary? Why did the zig-zag become larger or smaller when the parameters changed?
VegitableChicken
Same here, I remember the professor changed the two variables of the function, and at some point, decreasing the first parameter is easier to cause Z-fighting than increasing the second parameter. Can someone explain that?
JimL
I think (may not be correct) the main reason for z-fighting is the lack of numerical precision of float point, even the number is near to zero. According to the Opengl perspective matrix (slide 20), we can have a formula for Zp(z perspective): zp= (f+n)/(f-n)-2fn/((f-n)*z). Let A be (f+n)/(f-n) and B be 2fn/(f-n), then zp= A - B/z.
For the first part A, when f is very large or 1/n is very large, A->1, therefore this part is "kind of" OK.
For the second part B, let's think about the function 1/x. If B is very small, 1/x tend to be very flat when x>1. And this can cause that 1/(x+a)-1/(x) (a is a fair step) tends to be 0 and can not be represented by float point. So the next question is what causes B to be small? Only when n is close to 0, but not when f is large.
So when is the situation that "f is large causes z-fighting" comes into play? I think it is when the object is far away from the camera(z is large). For function 1/x, it tends to be flat as x going bigger. So when the object is far away from camera, z is very large and 1/(z+a)-1/(z) can not be represented by float point.
Max
Good explanation. To put it possibly more simply, we have to map z from [n,f] to [-1,1] in order to store it in the depth buffer. The easiest thing to do is a simple linear map, but we would rather store a linear function of 1/z. This is because 1/z is linear in screen space (allowing us to interpolate it over a screen-space triangle), and naturally arises from the perspective divide. Therefore, decreasing n toward zero means we have a much larger range ([1/f,1/n]) to cram into [-1,1], so there's less precision around each value. This also means we can increase f arbitrarily (in fact, to infinity) without losing a lot of precision, which is another benefit of storing a function of 1/z - we usually prioritize seeing far away over super close. You can take the limit f->infinity of the projection matrix to see how.
When professor was talking about this slide in today's lecture, he run some code and showed us a demo. Does anyone remember what the parameters that he adjusted while running the code mean? Why were there twinkling zig-zag patterns at the boundary? Why did the zig-zag become larger or smaller when the parameters changed?
Same here, I remember the professor changed the two variables of the function, and at some point, decreasing the first parameter is easier to cause Z-fighting than increasing the second parameter. Can someone explain that?
I think (may not be correct) the main reason for z-fighting is the lack of numerical precision of float point, even the number is near to zero. According to the Opengl perspective matrix (slide 20), we can have a formula for Zp(z perspective): zp= (f+n)/(f-n)-2fn/((f-n)*z). Let A be (f+n)/(f-n) and B be 2fn/(f-n), then zp= A - B/z.
For the first part A, when f is very large or 1/n is very large, A->1, therefore this part is "kind of" OK.
For the second part B, let's think about the function 1/x. If B is very small, 1/x tend to be very flat when x>1. And this can cause that 1/(x+a)-1/(x) (a is a fair step) tends to be 0 and can not be represented by float point. So the next question is what causes B to be small? Only when n is close to 0, but not when f is large.
So when is the situation that "f is large causes z-fighting" comes into play? I think it is when the object is far away from the camera(z is large). For function 1/x, it tends to be flat as x going bigger. So when the object is far away from camera, z is very large and 1/(z+a)-1/(z) can not be represented by float point.
Good explanation. To put it possibly more simply, we have to map z from [n,f] to [-1,1] in order to store it in the depth buffer. The easiest thing to do is a simple linear map, but we would rather store a linear function of 1/z. This is because 1/z is linear in screen space (allowing us to interpolate it over a screen-space triangle), and naturally arises from the perspective divide. Therefore, decreasing n toward zero means we have a much larger range ([1/f,1/n]) to cram into [-1,1], so there's less precision around each value. This also means we can increase f arbitrarily (in fact, to infinity) without losing a lot of precision, which is another benefit of storing a function of 1/z - we usually prioritize seeing far away over super close. You can take the limit f->infinity of the projection matrix to see how.
Here's an explanation of why we store 1/z and the best ways to do so: https://developer.nvidia.com/content/depth-precision-visualized
And here's a visualization of the effects of various depth buffer formats on precision: https://mynameismjp.wordpress.com/2010/03/22/attack-of-the-depth-buffer/