What if we get a point which lies in between the small square units (Cause from what I understood these represent the pixels of a screen)? Do we resolve it by approximation or do we calculate that point precisely?
Senbei
When I saw the 2D box we showing on the blackboard, I feel that it looks a bit weird.
So I tried to demo it in Unity.
I put a box with scale(2,2,2) at position(0,0,0).
And I put a camera with fov 90 at position(2,3,5), looking at direction(0,0,-1).
Here is the image I got:
https://drive.google.com/file/d/19msiaNPMVKX85B529J-AbTr9V_M41fvw/view?usp=sharing
Although the result from class and the result from Unity look a bit different(up-down flipped),
the overall shape is correct.
JimL
Want to explain the example a little bit. By doing the calculation "subtract camera from vertex (X,Y,Z) to get (x,y,z) and divide the (x,y) by z", we are setting the camera at (2,3,5) towards the -z(0,0,-1) direction(because of dividing (x,y) by z). Also, by "divide the (x,y) by z", we are applying the "pinhole" model stated in Slide 38. This also answer why the result of @Senbei's demo is up-down flipped.
dino
I found this part of lecture very interesting. We were able to take a 2D image and give it the appearance of a 3D cube, which is pretty cool. Looking forward to the rest of this course!
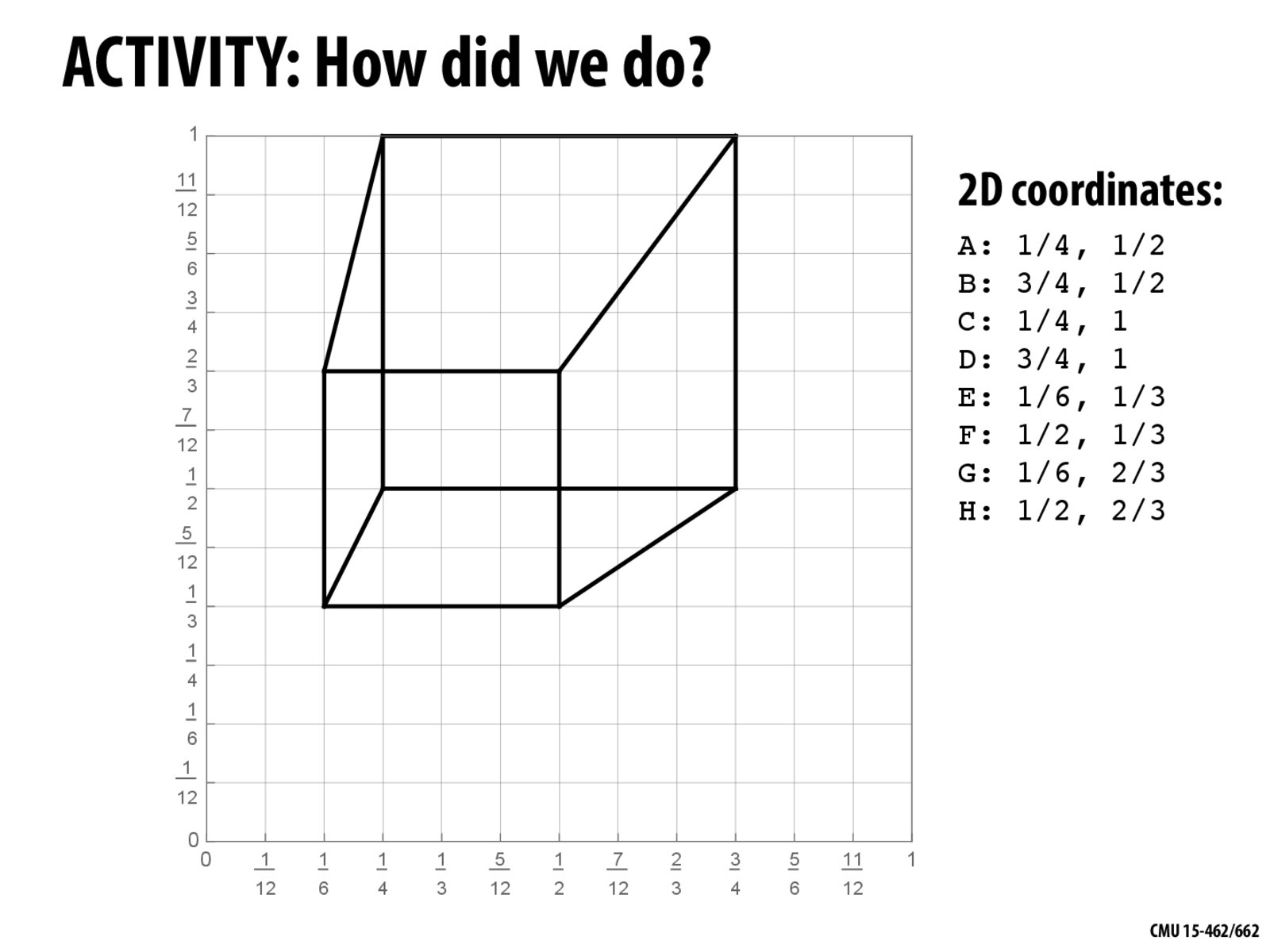
What if we get a point which lies in between the small square units (Cause from what I understood these represent the pixels of a screen)? Do we resolve it by approximation or do we calculate that point precisely?
When I saw the 2D box we showing on the blackboard, I feel that it looks a bit weird. So I tried to demo it in Unity. I put a box with scale(2,2,2) at position(0,0,0). And I put a camera with fov 90 at position(2,3,5), looking at direction(0,0,-1). Here is the image I got: https://drive.google.com/file/d/19msiaNPMVKX85B529J-AbTr9V_M41fvw/view?usp=sharing
Although the result from class and the result from Unity look a bit different(up-down flipped), the overall shape is correct.
Want to explain the example a little bit. By doing the calculation "subtract camera from vertex (X,Y,Z) to get (x,y,z) and divide the (x,y) by z", we are setting the camera at (2,3,5) towards the -z(0,0,-1) direction(because of dividing (x,y) by z). Also, by "divide the (x,y) by z", we are applying the "pinhole" model stated in Slide 38. This also answer why the result of @Senbei's demo is up-down flipped.
I found this part of lecture very interesting. We were able to take a 2D image and give it the appearance of a 3D cube, which is pretty cool. Looking forward to the rest of this course!