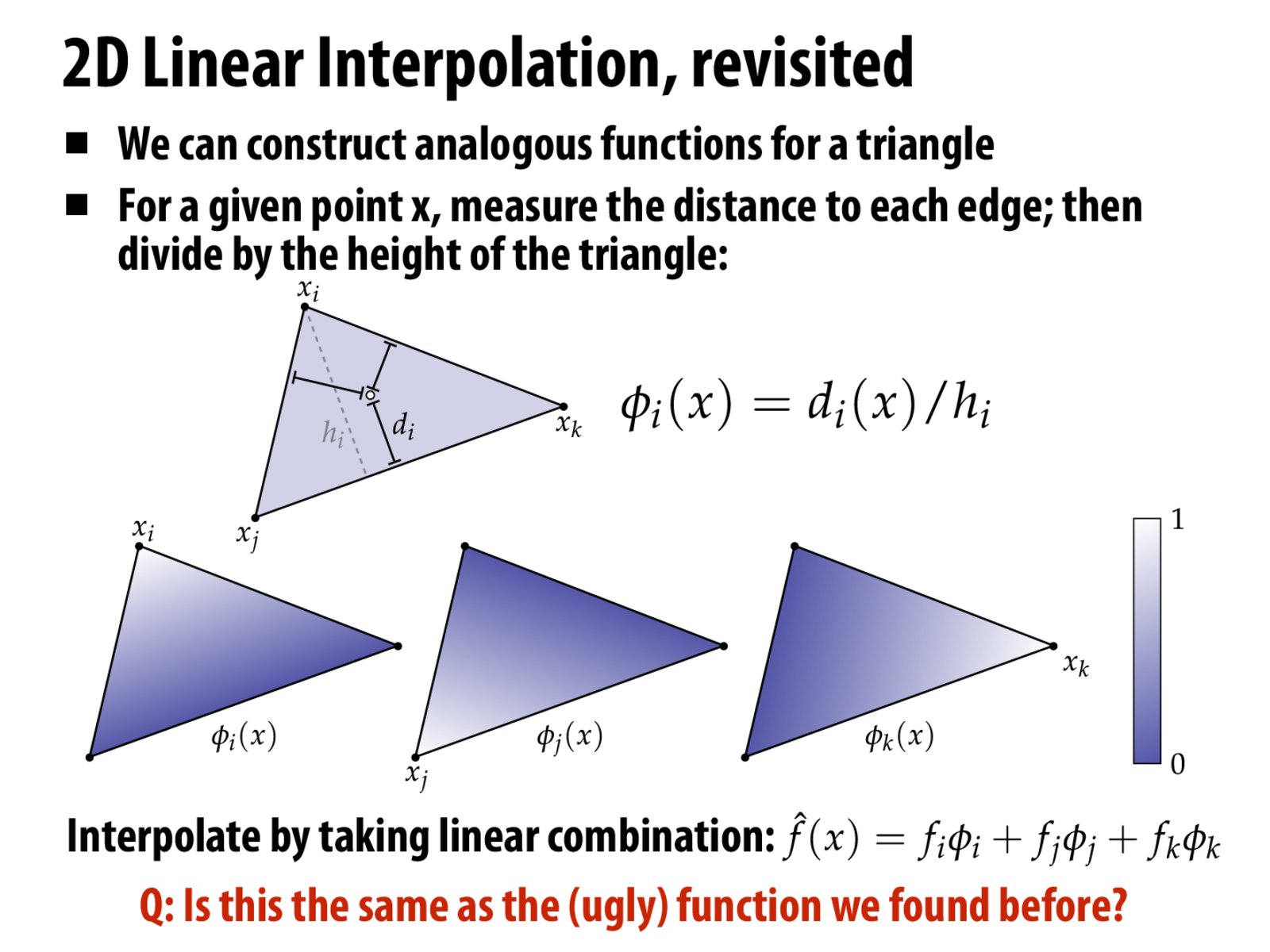
Mathematically, how do we compute the d_i's, and the h_i's? Isn't this computationally intensive as well?
saphirasnow
From the computer's perspective (which doesn't necessarily care how pretty/ugly a computation is, just operations), are we saving a significant amount of work by taking this approach?
gloose
Does this construction really capture closeness to a vertex, or just distance from the opposite edge? For example, if we take an equilateral triangle on the xy plane centered at x=0 with its base lying on the x axis, and we call the top vertex x_i = (0, h_i), then phi_i(x, y) = y/h_i is constant for all points with the same y coordinate, even though the point (0, y) is actually closer to x_i by Euclidean distance. Does the equation somehow account for this when you combine the three phi functions in the linear combination?
richardnnn
Why don't we just use the ratio of distance from the point to the three vertices? In order to satisfy similar "the closer, the larger" properties like area, we can "distribute" the distance from the point to a vertex to other two vertices evenly, and do the same for other two vertices, then calculate the percentage ratio.
Zishen
in term of the complexity of computation, are they the same?
jonasjiang
Is there any fast way to compute the height of the triangle?
kpshah
how is the calculation of d_i terms and h_i terms less computationally intensive?
gfkang
If the point is really close to x_j, then wouldn't d/h be greater than 1? Or is that ok?
spidey
Why do we use this method for doing this interpolation computation? Are there other faster or less intensive methods?
large_monkey
Is there a precise measurement on the number of instructions, or multiplications it would take to perform interpolation via these methods, as opposed to a generic brute-force solver (as discussed in a previous slide)? Intuitively, I'm still not convinced that this way is considerably faster, so maybe an example would be helpful.
Mathematically, how do we compute the d_i's, and the h_i's? Isn't this computationally intensive as well?
From the computer's perspective (which doesn't necessarily care how pretty/ugly a computation is, just operations), are we saving a significant amount of work by taking this approach?
Does this construction really capture closeness to a vertex, or just distance from the opposite edge? For example, if we take an equilateral triangle on the xy plane centered at x=0 with its base lying on the x axis, and we call the top vertex x_i = (0, h_i), then phi_i(x, y) = y/h_i is constant for all points with the same y coordinate, even though the point (0, y) is actually closer to x_i by Euclidean distance. Does the equation somehow account for this when you combine the three phi functions in the linear combination?
Why don't we just use the ratio of distance from the point to the three vertices? In order to satisfy similar "the closer, the larger" properties like area, we can "distribute" the distance from the point to a vertex to other two vertices evenly, and do the same for other two vertices, then calculate the percentage ratio.
in term of the complexity of computation, are they the same?
Is there any fast way to compute the height of the triangle?
how is the calculation of d_i terms and h_i terms less computationally intensive?
If the point is really close to x_j, then wouldn't d/h be greater than 1? Or is that ok?
Why do we use this method for doing this interpolation computation? Are there other faster or less intensive methods?
Is there a precise measurement on the number of instructions, or multiplications it would take to perform interpolation via these methods, as opposed to a generic brute-force solver (as discussed in a previous slide)? Intuitively, I'm still not convinced that this way is considerably faster, so maybe an example would be helpful.