Just to clarify, in a K-D tree, if a triangle span multiple partitioned spaces, each corresponding node in the K-D tree needs to store a reference to the triangle to handle the overlapping problem. Is this correct?
kkzhang
Is the back to front order relative to the direction of the ray? If so, would we have to recompute the tree every time the ray changes direction?
WhaleVomit
How are we choosing where to make the split, and how much to recurse on each side?
MrRockefeller
my takeaway is: the advantage of this method is every box is neighboring each other, so there is an if else statement we can probably ignore in the previous front to back algorithm slide
Starboy
Could we also try to transform a BVH into a K-D tree to make the two methods consistent?
yifanch3
what is the algorithms to generate this KD tree?
goose_r_s
Storing calculations in memory may be more expensive than recomputing it in certain applications on certain hardware. Does this mean algorithms can often be optimized to certain hardware for purposes like this?
anon
Is it relevant whether the two halves of the K-D tree are relatively balanced? Or does it not matter if the nodes all happen to be on one side?
large_monkey
I have heard that trees that partition space (like a quad tree, for instance) generally have bad algorithmic runtime guarantees. How does the kd-tree improve on these techniques? EDIT: I see this is covered in the rest of the lecture. But still it is not clear to me mathematically why the kd-tree is much better? Could we go through a proof of runtime, or at least an argument along those lines?
bobzhangyc
I am confused about the kd tree algorithm
ml2
I don't really understand why we can terminate after the first hit is found. How are primitives further back affected by those in front in terms of partitioning?
corgo
Is the reason behind terminating after first hit is that everything down the node will be further back in space, which will be covered by the current hit?
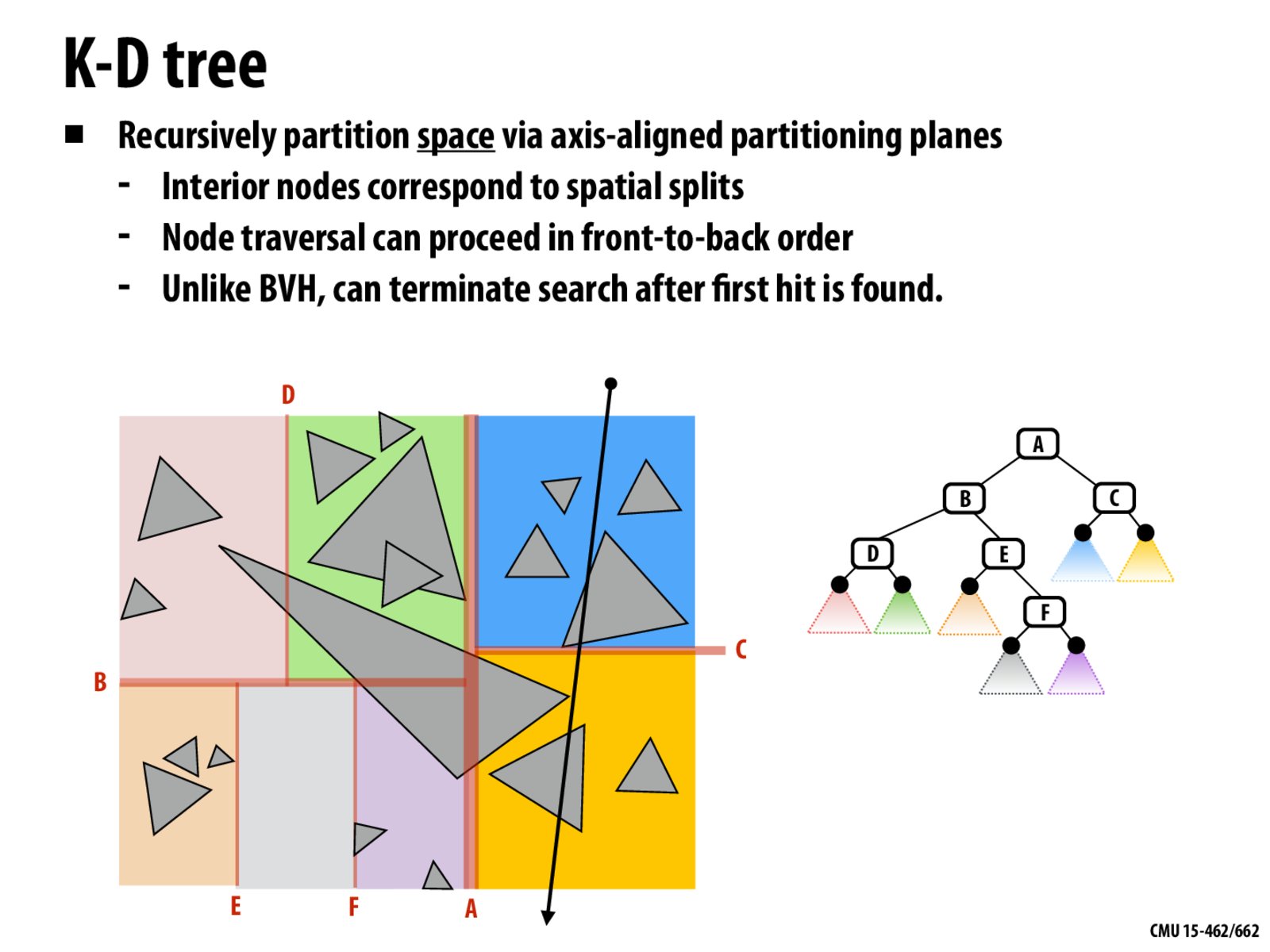
Just to clarify, in a K-D tree, if a triangle span multiple partitioned spaces, each corresponding node in the K-D tree needs to store a reference to the triangle to handle the overlapping problem. Is this correct?
Is the back to front order relative to the direction of the ray? If so, would we have to recompute the tree every time the ray changes direction?
How are we choosing where to make the split, and how much to recurse on each side?
my takeaway is: the advantage of this method is every box is neighboring each other, so there is an if else statement we can probably ignore in the previous front to back algorithm slide
Could we also try to transform a BVH into a K-D tree to make the two methods consistent?
what is the algorithms to generate this KD tree?
Storing calculations in memory may be more expensive than recomputing it in certain applications on certain hardware. Does this mean algorithms can often be optimized to certain hardware for purposes like this?
Is it relevant whether the two halves of the K-D tree are relatively balanced? Or does it not matter if the nodes all happen to be on one side?
I have heard that trees that partition space (like a quad tree, for instance) generally have bad algorithmic runtime guarantees. How does the kd-tree improve on these techniques? EDIT: I see this is covered in the rest of the lecture. But still it is not clear to me mathematically why the kd-tree is much better? Could we go through a proof of runtime, or at least an argument along those lines?
I am confused about the kd tree algorithm
I don't really understand why we can terminate after the first hit is found. How are primitives further back affected by those in front in terms of partitioning?
Is the reason behind terminating after first hit is that everything down the node will be further back in space, which will be covered by the current hit?