The title says "Efficiently", but this doesn't seem very efficient. What exactly makes this efficient?
asheng2
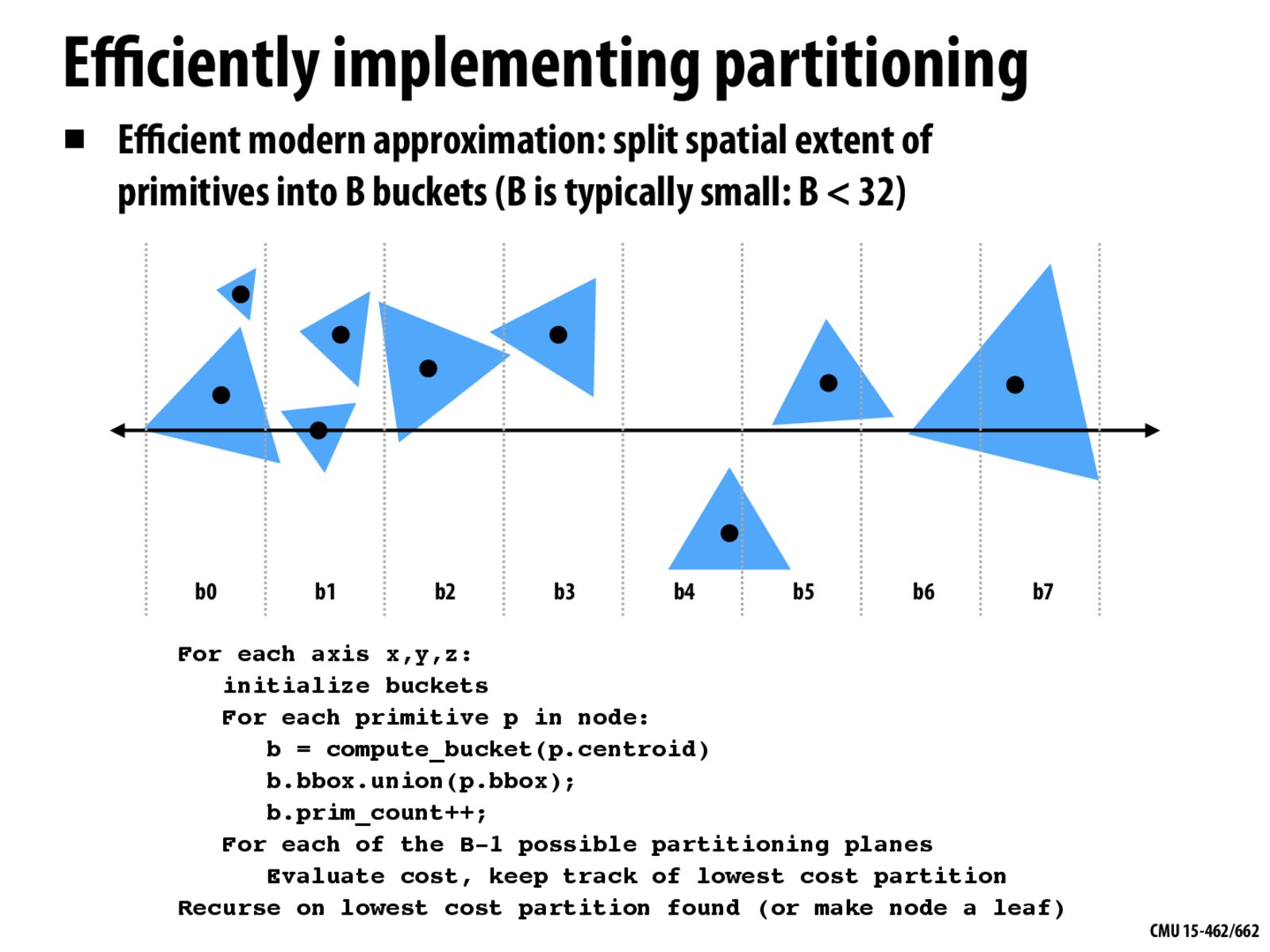
I'm a bit confused on how the buckets are used when evaluating the cost of the partitioning planes. When we are looking at a partitioning plane, are we looking at all the buckets to the left and right of that plane?
Midoriya
Can we use clustering algorithms like k-means?
kkzhang
Why do we have to go through each axis x, y, and z? Would this not lead to nondisjoint nodes?
MrRockefeller
i dont understand the recursive part, what are we recursing on?
jonasjiang
What is the base case of this recursive algorithm? Is it when we get a partition with nothing inside?
MrRockefeller
i think i understand it a bit now. you try a few times which 1 partition is good, apply it, and go to the next level until you reach every leaf
ScreenTime
Is this similar to clustering?
Murrowow
I'm a bit confused on how exactly the recursive functions work. Are we recursively splitting into boxes and checking if there's a leaf inside? If there isn't that's our base case?
anon
Why is having a constant (soft?) limit on the number of buckets better than having the number of buckets more or less scale slowly with the number of items to be partitioned?
anj
Is node leaf the base case? Do we case on it to determine the recursion?
spidey
How is this algorithm necessarily efficient? Are there other ways to partition that approximate more quickly?
bobzhangyc
What is the cost of splitting? nlogn?
corgo
I'm confused on the recursion part as well. Can we go through it more indepth in class?
The title says "Efficiently", but this doesn't seem very efficient. What exactly makes this efficient?
I'm a bit confused on how the buckets are used when evaluating the cost of the partitioning planes. When we are looking at a partitioning plane, are we looking at all the buckets to the left and right of that plane?
Can we use clustering algorithms like k-means?
Why do we have to go through each axis x, y, and z? Would this not lead to nondisjoint nodes?
i dont understand the recursive part, what are we recursing on?
What is the base case of this recursive algorithm? Is it when we get a partition with nothing inside?
i think i understand it a bit now. you try a few times which 1 partition is good, apply it, and go to the next level until you reach every leaf
Is this similar to clustering?
I'm a bit confused on how exactly the recursive functions work. Are we recursively splitting into boxes and checking if there's a leaf inside? If there isn't that's our base case?
Why is having a constant (soft?) limit on the number of buckets better than having the number of buckets more or less scale slowly with the number of items to be partitioned?
Is node leaf the base case? Do we case on it to determine the recursion?
How is this algorithm necessarily efficient? Are there other ways to partition that approximate more quickly?
What is the cost of splitting? nlogn?
I'm confused on the recursion part as well. Can we go through it more indepth in class?