This is only efficient for a static scene with multiple rays being casted, right? If there is motion, you would need to recalculate the BVH every time step. Does motion make this inefficient?
daria
How are we defining the comparison operation here
ShallowDream
Is it possible to use an arbitrary amount of children?
MrRockefeller
I think the better one should be the one with less branches (entropies) that can lead to every single element, like the concept in decision tree
MrRockefeller
But we need to consider the "density" in the boxes too...like how many triangles per area it has, so I guess the entropy idea isn't the best. I am very curious about this problems' optimized steps.
twizzler
This reminds me a lot of the Barnes-Hutt trick for efficiently computing n-body interactions in space. Was any inspiration taken from that algorithm in making this technique?
Starboy
Is finding a bounding box that is as large as possible always a better choice?
yifanch3
But in this method, how should we control the grain of the smaller cluster box?
If we define too many small boxes, would the situation back into normal condition?
air-wreck
Is there a fast way to update the bounding volumes if we add something to the scene?
Oh_skr
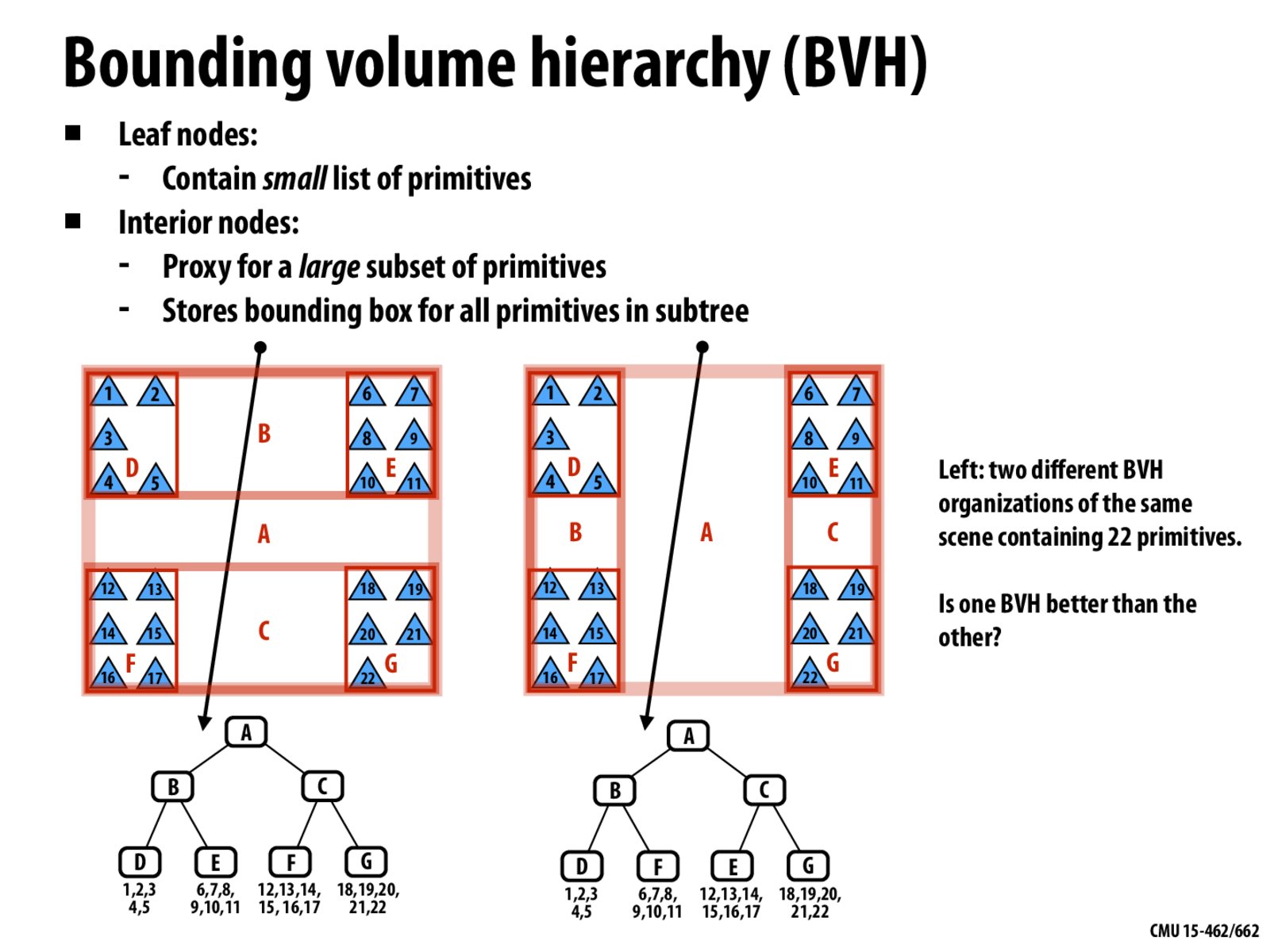
Is the right BVH always better? If I know most of the rays in a scene are horizontal, wouldn't the left BVH be better?
dab
The trees shown are always full, is that a property we should try to achieve? In what situation might you want a non-full tree?
abigalekim
are the leaves sorted by pixel order?
embl
When doing motion capture, I see that often the output extension file has .bvh. Does it refer to the BVH introduced in this lecture?
anj
How would we compare one to the other?
Concurrensee
is there possible of duplicated bounding box or other duplicated data? In this case, can we drop some duplicated data to optimize efficiency?
Bellala
What is the work and span of doing such computation?
ant123
What are the benefits of doing one version of volume bounding vs the other?
L1TTLEM4N
What if there are rays coming from other directions? Would that make one better than the other?
This is only efficient for a static scene with multiple rays being casted, right? If there is motion, you would need to recalculate the BVH every time step. Does motion make this inefficient?
How are we defining the comparison operation here
Is it possible to use an arbitrary amount of children?
I think the better one should be the one with less branches (entropies) that can lead to every single element, like the concept in decision tree
But we need to consider the "density" in the boxes too...like how many triangles per area it has, so I guess the entropy idea isn't the best. I am very curious about this problems' optimized steps.
This reminds me a lot of the Barnes-Hutt trick for efficiently computing n-body interactions in space. Was any inspiration taken from that algorithm in making this technique?
Is finding a bounding box that is as large as possible always a better choice?
But in this method, how should we control the grain of the smaller cluster box? If we define too many small boxes, would the situation back into normal condition?
Is there a fast way to update the bounding volumes if we add something to the scene?
Is the right BVH always better? If I know most of the rays in a scene are horizontal, wouldn't the left BVH be better?
The trees shown are always full, is that a property we should try to achieve? In what situation might you want a non-full tree?
are the leaves sorted by pixel order?
When doing motion capture, I see that often the output extension file has .bvh. Does it refer to the BVH introduced in this lecture?
How would we compare one to the other?
is there possible of duplicated bounding box or other duplicated data? In this case, can we drop some duplicated data to optimize efficiency?
What is the work and span of doing such computation?
What are the benefits of doing one version of volume bounding vs the other?
What if there are rays coming from other directions? Would that make one better than the other?