How does applying the inverse of the hessian add a quadratic term of optimization?
niyiqiul
Are methods involving higher-order momentums better suited for non-convex problems?
Midoriya
For nonconvex problems, can we do gradient descent with random restarts?
twizzler
Are algorithms from machine learning applied here (random starts, random walking with k walkers, etc)?
aa4
In the lecture, you mentioned that the sign of Hessian flips as we move from x_k to to x*. I didn't quite get why is that the case? Shouldn't it be always positive as it positive semi-definite?
coolpotato
In the video, you said we use the inverse of the Hessian as it would be part of the 2nd order Taylor approximation of f. Would using a higher order derivative than the Hessian further help create that "bowl-like" structure? And if so, what kind of tradeoffs are there? Specifically, does it help save time?
WhaleVomit
Is it practical to use 3rd degree or above order descents?
corgo
How costly would it be to use 3 or above order descents? Is it worth it?
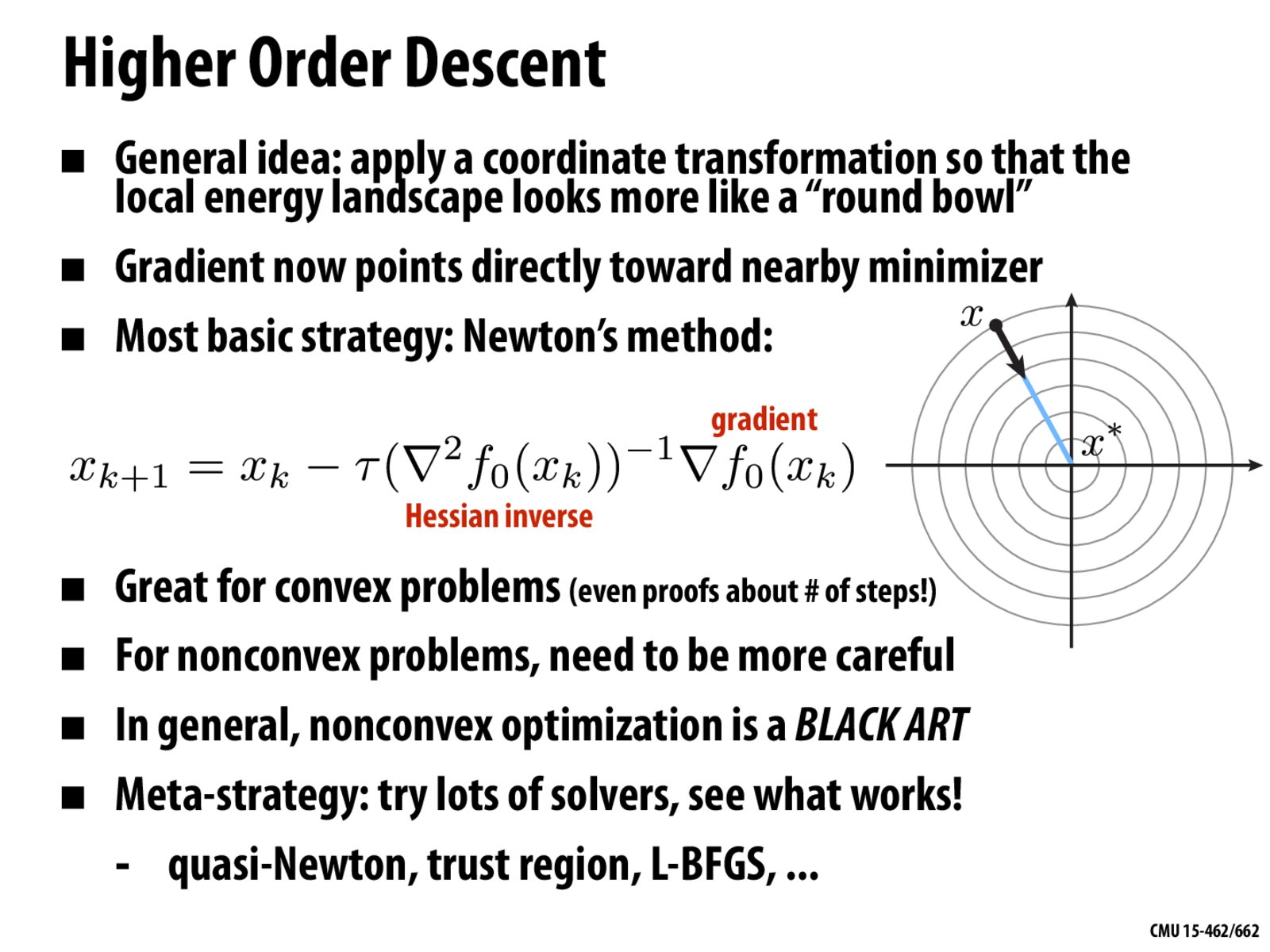
How is Newton's method equation mapped to a disc?
How does applying the inverse of the hessian add a quadratic term of optimization?
Are methods involving higher-order momentums better suited for non-convex problems?
For nonconvex problems, can we do gradient descent with random restarts?
Are algorithms from machine learning applied here (random starts, random walking with k walkers, etc)?
In the lecture, you mentioned that the sign of Hessian flips as we move from x_k to to x*. I didn't quite get why is that the case? Shouldn't it be always positive as it positive semi-definite?
In the video, you said we use the inverse of the Hessian as it would be part of the 2nd order Taylor approximation of f. Would using a higher order derivative than the Hessian further help create that "bowl-like" structure? And if so, what kind of tradeoffs are there? Specifically, does it help save time?
Is it practical to use 3rd degree or above order descents?
How costly would it be to use 3 or above order descents? Is it worth it?