This cube still looks somewhat strange. What are the limitations in this approach that lead to its shortcomings? How would you do better?
Tinkay1120
The cube looks different when I see it in a different direction. It's hard to tell whether the large or small square is in the front. How can we improve this?
kkzhang
Does the cube look "strange" because we are used to seeing it in 3D from a camera in front of the cube rather than behind?
asheng2
What causes the front and back face of the cube to appear different sizes? Is it due to how we are projecting the cube, the pinhole camera model, or some other factor?
blahaj
Is there a way to determine whether [part of] an edge is "behind" another one? This way, we could make the far overlapped edges a lighter color to show which face is actually in the front.
BlueCat
I think this is how the camera sees the cube, but why we need the camera in graphics? Is it because we need the camera to convert 3D shape into 2D?
ant123
Why is the back face of the cube so much larger than the front? How can we correct for this visually?
norgate
Piggybacking on the comments about the back face of the cube being in front of vs behind the other, will we need to encode more data in the cube to account for that? Or do we just need to color the cube such that the smaller square is all shaded in, based off the camera location?
urae
How can we determine the position of the camera and the focal point from graphs like these?
air54321
The cube does not look like what I typically imagine a rendered cube should like (more evenly distributed, rather than staggered). I know this is due to the position of the camera relative to the origin, but is there a way to visualize this better? It is hard to imagine a camera floating in some arbitrary 3D location when our model is 2D.
Concurrensee
I think human eyes view is different from single point view. Can we draw a picture based on two points just like human eyes?
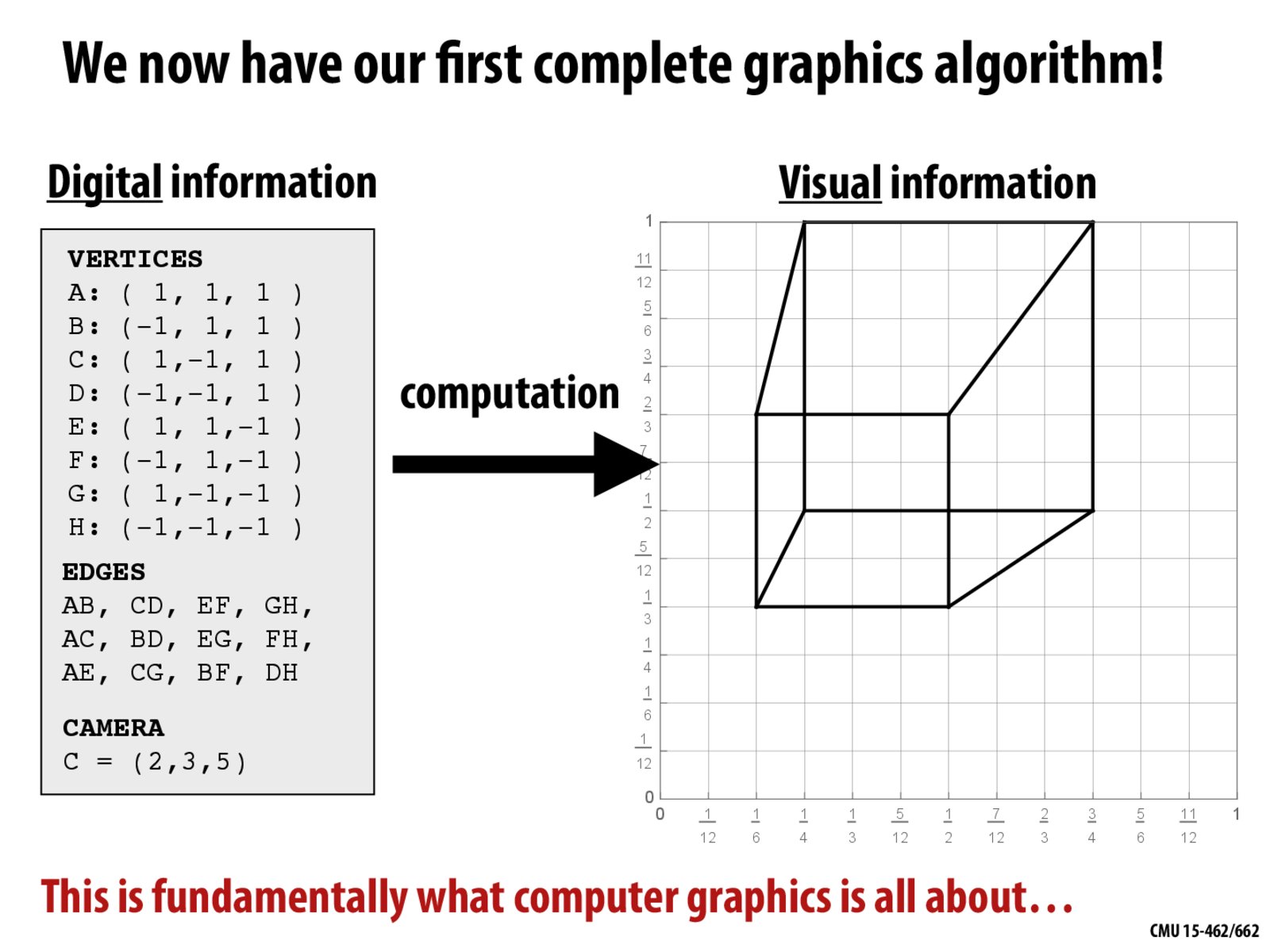
This cube still looks somewhat strange. What are the limitations in this approach that lead to its shortcomings? How would you do better?
The cube looks different when I see it in a different direction. It's hard to tell whether the large or small square is in the front. How can we improve this?
Does the cube look "strange" because we are used to seeing it in 3D from a camera in front of the cube rather than behind?
What causes the front and back face of the cube to appear different sizes? Is it due to how we are projecting the cube, the pinhole camera model, or some other factor?
Is there a way to determine whether [part of] an edge is "behind" another one? This way, we could make the far overlapped edges a lighter color to show which face is actually in the front.
I think this is how the camera sees the cube, but why we need the camera in graphics? Is it because we need the camera to convert 3D shape into 2D?
Why is the back face of the cube so much larger than the front? How can we correct for this visually?
Piggybacking on the comments about the back face of the cube being in front of vs behind the other, will we need to encode more data in the cube to account for that? Or do we just need to color the cube such that the smaller square is all shaded in, based off the camera location?
How can we determine the position of the camera and the focal point from graphs like these?
The cube does not look like what I typically imagine a rendered cube should like (more evenly distributed, rather than staggered). I know this is due to the position of the camera relative to the origin, but is there a way to visualize this better? It is hard to imagine a camera floating in some arbitrary 3D location when our model is 2D.
I think human eyes view is different from single point view. Can we draw a picture based on two points just like human eyes?
Is there any other ways to do this?