Does it make a difference that the perspective is flipped? As in, the triangles are similar so we can find the absolute value of v, but are we also going to need to use a negative sign to account for the position of q being above or below that center horizontal line?
bobzhangyc
The unit is set to be 1, what if it changes? Plus, the eye is different from the pinhole.
Starboy
Will the size of the pinhole matter here? For the calculations in this slide, it seems that we assume the size of the pinhole is infinitely small. But if the pinhole has a length of h, let's say, would there be any difference?
corgo
Does our eyes function exactly the same way as the pinhole, but just flipped?
kkzhang
What would happen if the camera is not perfectly square? eg. if the pinhole face or the image face was tilted
asheng2
If we also want to capture the shadows of an object, such as the tree, would the same calculations here with the image coordinates work?
BlueCat
What do x in p and u in q measure for since they are not shown in the picture? Why we treat the image width as 1?
bunnybun99
Could you explain how are x and z related and how the horizontal coordinate u is calculated? Since the relation of x and z is not drawn in the slide, I'm having difficulty visualizing it.
Olivia
Thinking of an eye as a pinhole, is the distance (1) in the image equal to the distance between the cornea and the lens? If not, what is the "pinhole" and what is the "photo paper"? Also, how does changing the size of the pinhole (if that can be the analogue of the dilation of a pupil) change the equations?
daria
Is the x coordinate "depth" in this case?
ant123
Is there any particular reason we choose the image width to be 1? Or is that just for convenience?
Also, for the top box view (calculating the horizontal coordinate u), would it be correct to assume that z represents the distance of the tree from the image, while x would be the leaf's distance above the horizontal line (and u is the distance below the line)?
Coyote
A long time ago I watched a video about 3D projection onto a 2D plane and vaguely remember something that mentioned the need for a smaller "close z" that represents the distance between the viewer's head and the screen since the viewer never actually has their face pressed right up against a computer screen. So in the case that I'm thinking of, the vertical plane that point c resides on would represent the screen itself, while the vertical plane point q resides on might represent where the viewer's head might be. Does the similar triangle with a length/width of 1 serve this purpose, or am I remembering something completely different? The more I write the more incorrect my assumption sounds, especially since this type of projection seems to be more of a "camera obscura" type of projection.
Also, the field of view is a cone, right? x is into/out of the screen, y is height, z is width, etc?
large_monkey
It seems rather inefficient to have to project point by point individually. In the example of the cube it is easy to project all the vertices and then connect them. However for more complicated shapes we may not necessarily have many straight lines edges and so it may not be so straightforward to do this. How does one go about doing this in the general case in an efficient manner?
ml2
Could also we take into account and translate the intensity of the coordinate through a variation of this method?
anj
I'm wondering how people made this pinhole accurate to the eye? Or if not, why is this accepted?
jefftan
I'm wondering how we can map from a 3D world (x,y,z) to a 2D image (u,v). It seems like there is a lot of ambiguity since many points may map onto the same image pixel. Is this the principle behind stereo vision to be able to estimate depth from images taken using multiple camera views?
zeyuwang
Can we change the shape of the camera? What will happen if the shape of the camera is a triangle?
MrRockefeller
An implementation question, for example a tree here. It has so many points, but only about half of them need to be projected to a 2D screen, and it can save computational cost and time to only calculate the half. My question is in CAD software, when we change a viewpoint, does it always recalculate every points' projection? Or is there an easy way to ignore the points that won't be seen?
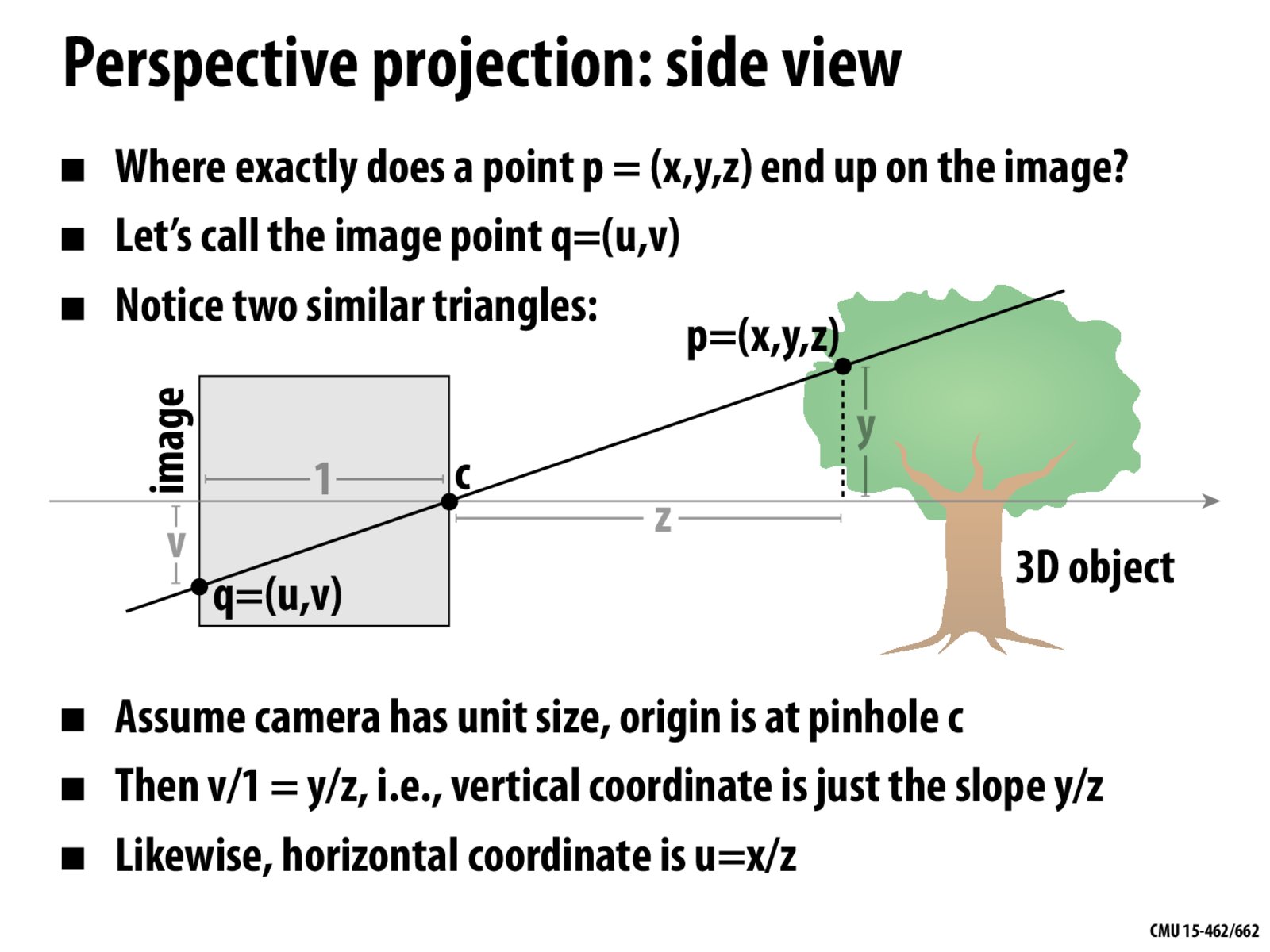
Does it make a difference that the perspective is flipped? As in, the triangles are similar so we can find the absolute value of v, but are we also going to need to use a negative sign to account for the position of q being above or below that center horizontal line?
The unit is set to be 1, what if it changes? Plus, the eye is different from the pinhole.
Will the size of the pinhole matter here? For the calculations in this slide, it seems that we assume the size of the pinhole is infinitely small. But if the pinhole has a length of h, let's say, would there be any difference?
Does our eyes function exactly the same way as the pinhole, but just flipped?
What would happen if the camera is not perfectly square? eg. if the pinhole face or the image face was tilted
If we also want to capture the shadows of an object, such as the tree, would the same calculations here with the image coordinates work?
What do x in p and u in q measure for since they are not shown in the picture? Why we treat the image width as 1?
Could you explain how are x and z related and how the horizontal coordinate u is calculated? Since the relation of x and z is not drawn in the slide, I'm having difficulty visualizing it.
Thinking of an eye as a pinhole, is the distance (1) in the image equal to the distance between the cornea and the lens? If not, what is the "pinhole" and what is the "photo paper"? Also, how does changing the size of the pinhole (if that can be the analogue of the dilation of a pupil) change the equations?
Is the x coordinate "depth" in this case?
Is there any particular reason we choose the image width to be 1? Or is that just for convenience?
Also, for the top box view (calculating the horizontal coordinate u), would it be correct to assume that z represents the distance of the tree from the image, while x would be the leaf's distance above the horizontal line (and u is the distance below the line)?
A long time ago I watched a video about 3D projection onto a 2D plane and vaguely remember something that mentioned the need for a smaller "close z" that represents the distance between the viewer's head and the screen since the viewer never actually has their face pressed right up against a computer screen. So in the case that I'm thinking of, the vertical plane that point c resides on would represent the screen itself, while the vertical plane point q resides on might represent where the viewer's head might be. Does the similar triangle with a length/width of 1 serve this purpose, or am I remembering something completely different? The more I write the more incorrect my assumption sounds, especially since this type of projection seems to be more of a "camera obscura" type of projection. Also, the field of view is a cone, right? x is into/out of the screen, y is height, z is width, etc?
It seems rather inefficient to have to project point by point individually. In the example of the cube it is easy to project all the vertices and then connect them. However for more complicated shapes we may not necessarily have many straight lines edges and so it may not be so straightforward to do this. How does one go about doing this in the general case in an efficient manner?
Could also we take into account and translate the intensity of the coordinate through a variation of this method?
I'm wondering how people made this pinhole accurate to the eye? Or if not, why is this accepted?
I'm wondering how we can map from a 3D world (x,y,z) to a 2D image (u,v). It seems like there is a lot of ambiguity since many points may map onto the same image pixel. Is this the principle behind stereo vision to be able to estimate depth from images taken using multiple camera views?
Can we change the shape of the camera? What will happen if the shape of the camera is a triangle?
An implementation question, for example a tree here. It has so many points, but only about half of them need to be projected to a 2D screen, and it can save computational cost and time to only calculate the half. My question is in CAD software, when we change a viewpoint, does it always recalculate every points' projection? Or is there an easy way to ignore the points that won't be seen?