If we use the "pinhole" model to simulate how human eyes perceive 3D objects, would the difference among every single eye matter? Is there an easy model that could adapt to this kind of difference?
YutianW
If we construct the graph this way, we may need to do this computation for each coordinate of each object in our model. Wouldn't that be rather computationally heavy? For example, if we have a cube we would do the calculation for 8 coordinates, but if we have 100 cubes, we would have 800 calculations and that computation is not limited by the total number of pixels, but rather the total coordinates of the objects.
Kaxano
It doesn't seem possible to determine the depth of an object (big tree far away vs small tree nearby) using an image generated with a pinhole model. Is there any modification to the model or to the resulting image that can be done to allow depth to be distinguished better by the viewer of the image?
clivehaha
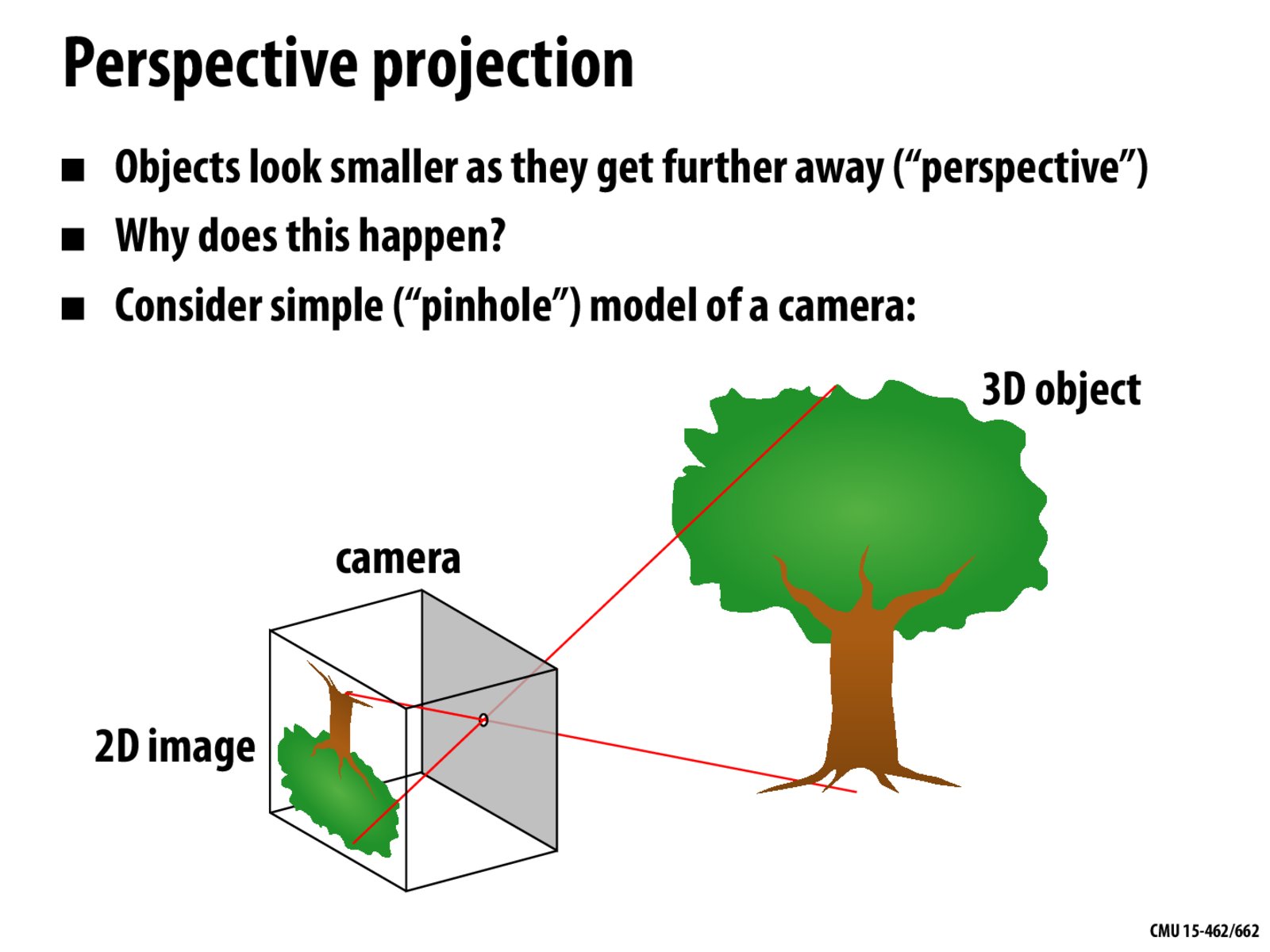
I'm wondering if there's a small mistake in the picture? The 2D image of the tree should be central symmetry to the 3D object. But if we look into the detail of the picture, it seems that the 2D image is actually upside down and smaller compared to the real one.
Mogician
How can depth of field be illustrated with this model?
kinematics
How does this relate to the concept of "focus" and being "nearsighted" or "farsighted"? If our location as viewer impacts how the 3D object appears to us (in 2D), it seems our location would similarly impact what we can focus on in our field of view.
kpshah
Since the pinhole camera is comparable to how our eyes work, would two pinhole cameras be needed to properly assess depth, since human depth perception is formed as a combination what both eyes take in?
zeyuwang
What's the difference between using pinhole and lens?
If we use the "pinhole" model to simulate how human eyes perceive 3D objects, would the difference among every single eye matter? Is there an easy model that could adapt to this kind of difference?
If we construct the graph this way, we may need to do this computation for each coordinate of each object in our model. Wouldn't that be rather computationally heavy? For example, if we have a cube we would do the calculation for 8 coordinates, but if we have 100 cubes, we would have 800 calculations and that computation is not limited by the total number of pixels, but rather the total coordinates of the objects.
It doesn't seem possible to determine the depth of an object (big tree far away vs small tree nearby) using an image generated with a pinhole model. Is there any modification to the model or to the resulting image that can be done to allow depth to be distinguished better by the viewer of the image?
I'm wondering if there's a small mistake in the picture? The 2D image of the tree should be central symmetry to the 3D object. But if we look into the detail of the picture, it seems that the 2D image is actually upside down and smaller compared to the real one.
How can depth of field be illustrated with this model?
How does this relate to the concept of "focus" and being "nearsighted" or "farsighted"? If our location as viewer impacts how the 3D object appears to us (in 2D), it seems our location would similarly impact what we can focus on in our field of view.
Since the pinhole camera is comparable to how our eyes work, would two pinhole cameras be needed to properly assess depth, since human depth perception is formed as a combination what both eyes take in?
What's the difference between using pinhole and lens?