To clarify, it seems like with the z buffer method they calculate occlusion point by point rather than primitive by primitive, is this the same with semi-transparent pixels we discuss later?
minhsual
Is this method efficient enough? Because it seems like it is redrawing a portion of the shape on top of each other whenever there is one with smaller depth. In the case of drawing triangles largely overlap with each other and are somehow order from the farthest to the closest, wouldn't this method be a lot slower to perform?
twizzler
Would the best way to parallelize this occlusion test be to do the computation per-triangle or per-pixel? Does it come down to optimization factors (locality, locking, etc.) or is there a correctness issue with doing it one of these ways?
corgo
Wouldn't this lead to very bizarre images if the sample rate is not high enough?
jonasjiang
What if a sample point is on the edge of interpenetration? Is it rendered with color of the shallower triangle?
Murrowow
This seems acceptable at a lower level, but I feel like there could be certain bugs that arise from this (inefficient from having to redraw something out in the front or potential sampling issues).
anon
Is there a minimum number of/spread of samples that are needed to render this? e.g. how would the method know that the line segment of intersection between the triangles is at a certain point or starts and ends at certain points if there wasn't a sample on the exact segment?
Concurrensee
What is they are at the same depth?
spidey
How many sample points are usually required for us to develop a good enough image based on the relative depth?
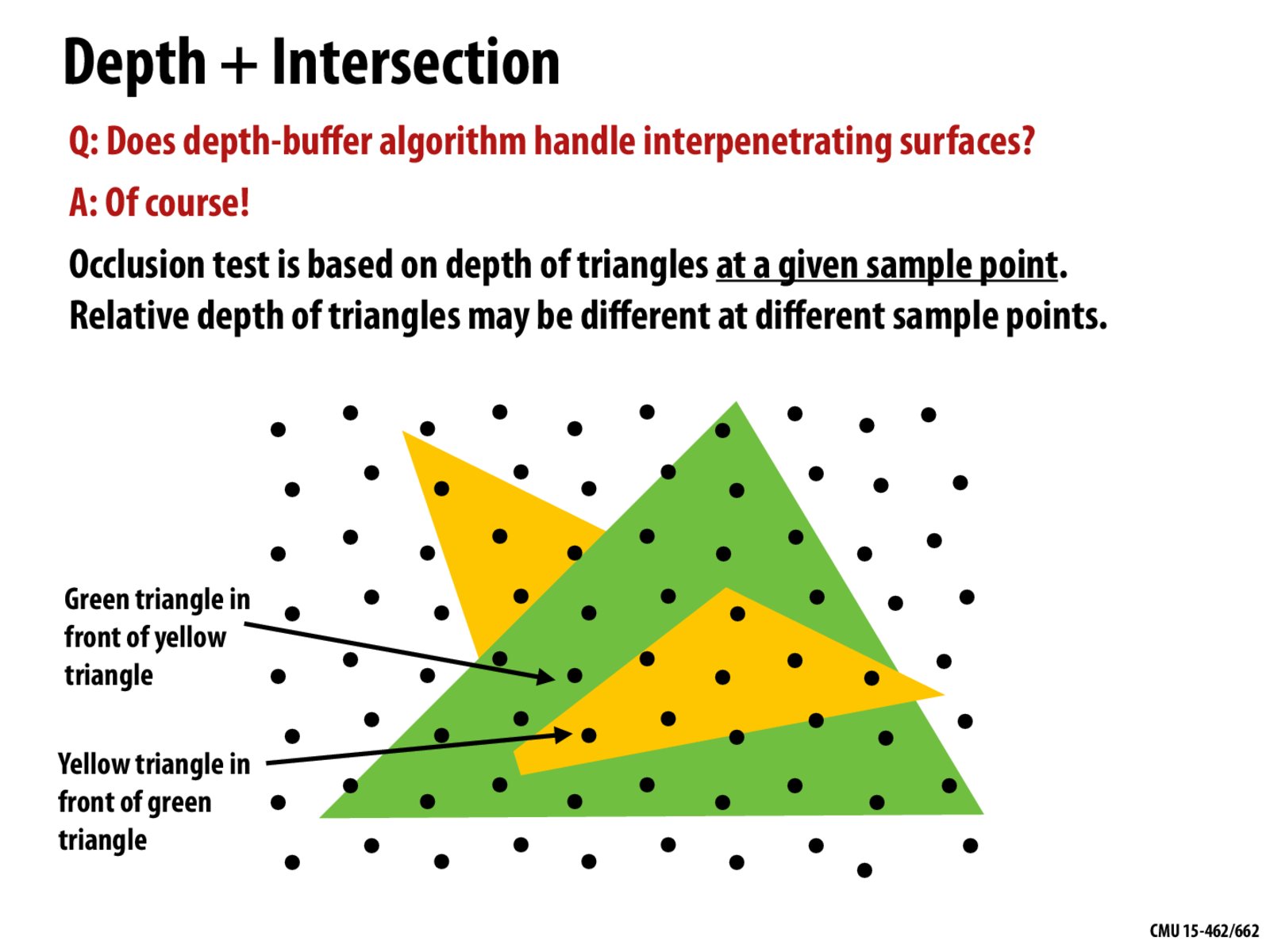
To clarify, it seems like with the z buffer method they calculate occlusion point by point rather than primitive by primitive, is this the same with semi-transparent pixels we discuss later?
Is this method efficient enough? Because it seems like it is redrawing a portion of the shape on top of each other whenever there is one with smaller depth. In the case of drawing triangles largely overlap with each other and are somehow order from the farthest to the closest, wouldn't this method be a lot slower to perform?
Would the best way to parallelize this occlusion test be to do the computation per-triangle or per-pixel? Does it come down to optimization factors (locality, locking, etc.) or is there a correctness issue with doing it one of these ways?
Wouldn't this lead to very bizarre images if the sample rate is not high enough?
What if a sample point is on the edge of interpenetration? Is it rendered with color of the shallower triangle?
This seems acceptable at a lower level, but I feel like there could be certain bugs that arise from this (inefficient from having to redraw something out in the front or potential sampling issues).
Is there a minimum number of/spread of samples that are needed to render this? e.g. how would the method know that the line segment of intersection between the triangles is at a certain point or starts and ends at certain points if there wasn't a sample on the exact segment?
What is they are at the same depth?
How many sample points are usually required for us to develop a good enough image based on the relative depth?