This book got me through the gradient descent assignment in 10601 and it's a really interesting read if anyone cared to learn more about convex optimization
pw123
What classes at cmu teach nonconvex optimization if there are any?
L100magikarp
10-725 spends some time on nonconvex optimization
keenan
@small_potato__ Yes, Boyd and Vandenberghe's book is a classic. And it's free! I strongly recommend you start there: learning convex optimization deeply will put you on far more solid footing to understand optimization in general than if you start out with general, nonconvex optimization. There's a real theory for the former; the rest is just a jungle...
Arthas007
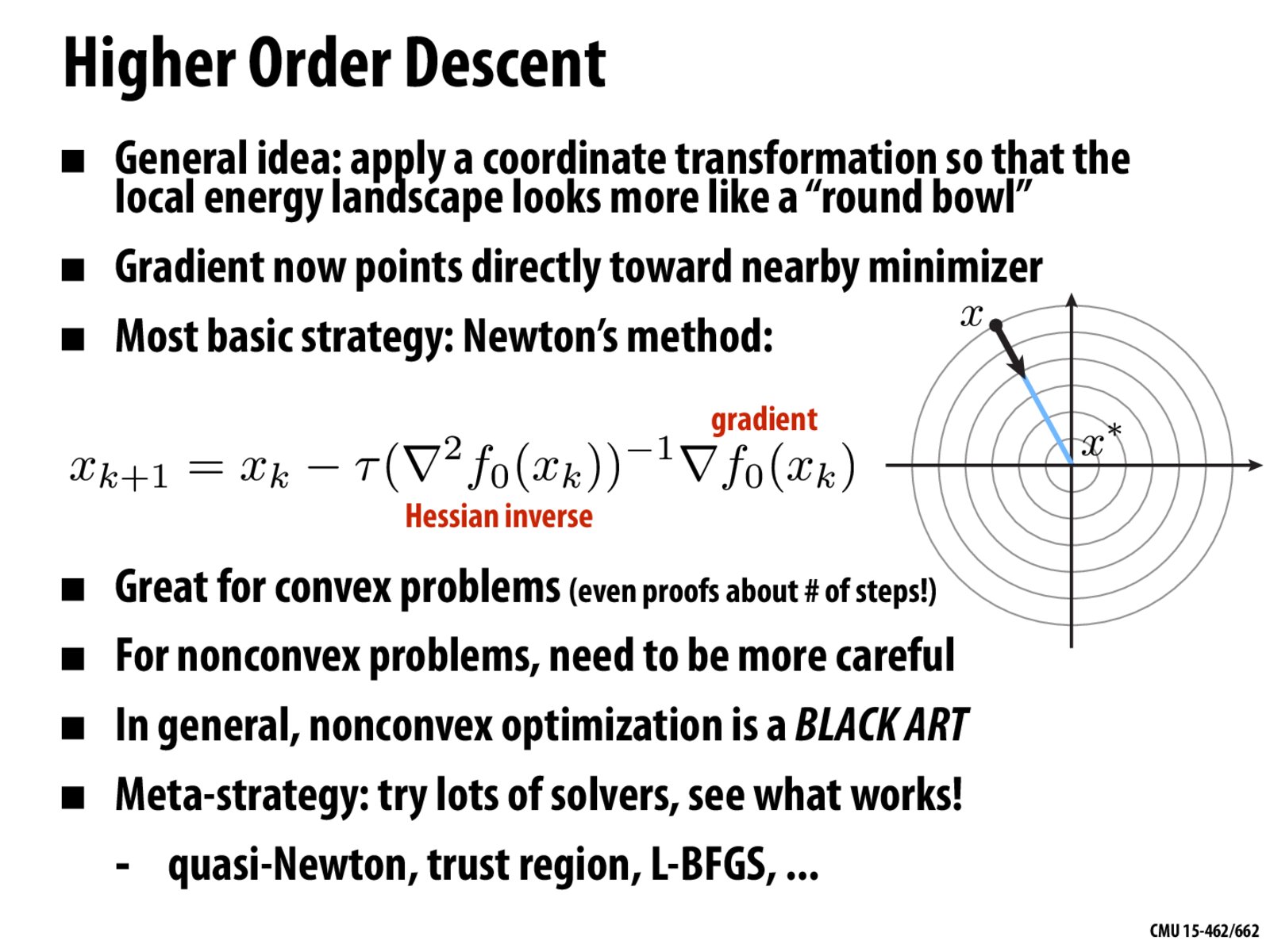
One question, the slide said the gradient descent found the local minimizer, however, is it possible for the process to be "trapped" in a local minimum when a better global minimum is possible to reach?
keenan
@Arthas007 Yes, easily. This happens all the time. And so people come up with all sorts of heuristics for finding better local minima (i.e., smaller energy). It's also why convex problems are nice: you can generally find the global minimum by just "skiing downhill." No local minima to get trapped in.
This is by the way a different way of looking at the hardness of computational problems. Finding the global minimum of some optimization problems is just as hard as any problem in NP; likewise, you can sometimes transform combinatorial problems (say, boolean satisfiability) into optimization problems---making it clear that finding global minima ain't easy!
0x484884
I've seen both the Hessian matrix and the Laplacian described as generalizations of the second derivative but the Laplacian is a scalar and is equal to the trace of the Hessian so it seems like it would lose all of the information about the mixed derivatives. When does it make sense to use the Laplacian vs the Hessian since I've seen both in formulas?
0x484884
Also, I would think that if the Laplacian doesn't include the mixed derivatives, then a surface that is concave up along the x and y axis but concave down on the diagonals y = x and y = -x should have a positive Laplacian. But if we change the basis vectors from pointing along the x and y axis to the diagonals y = x and y = -x, then wouldn't the surface now be concave down along the new axes so the Laplacian would become negative in the new basis?
It seems like the determinant of the Hessian would make more sense if we want to represent the 2nd derivative as just a scalar.
keenan
@0x484884 Good question. The Laplacian is invariant to a choice of coordinates. One way to understand this is that the Laplacian is the trace of the Hessian, and the trace is invariant to a choice of coordinates. (For instance, with an ordinary matrix the trace is equal to the sum of the eigenvalues, and eigenvalues are a geometric quantity that does not depend on coordinates.)
This book got me through the gradient descent assignment in 10601 and it's a really interesting read if anyone cared to learn more about convex optimization
What classes at cmu teach nonconvex optimization if there are any?
10-725 spends some time on nonconvex optimization
@small_potato__ Yes, Boyd and Vandenberghe's book is a classic. And it's free! I strongly recommend you start there: learning convex optimization deeply will put you on far more solid footing to understand optimization in general than if you start out with general, nonconvex optimization. There's a real theory for the former; the rest is just a jungle...
One question, the slide said the gradient descent found the local minimizer, however, is it possible for the process to be "trapped" in a local minimum when a better global minimum is possible to reach?
@Arthas007 Yes, easily. This happens all the time. And so people come up with all sorts of heuristics for finding better local minima (i.e., smaller energy). It's also why convex problems are nice: you can generally find the global minimum by just "skiing downhill." No local minima to get trapped in.
This is by the way a different way of looking at the hardness of computational problems. Finding the global minimum of some optimization problems is just as hard as any problem in NP; likewise, you can sometimes transform combinatorial problems (say, boolean satisfiability) into optimization problems---making it clear that finding global minima ain't easy!
I've seen both the Hessian matrix and the Laplacian described as generalizations of the second derivative but the Laplacian is a scalar and is equal to the trace of the Hessian so it seems like it would lose all of the information about the mixed derivatives. When does it make sense to use the Laplacian vs the Hessian since I've seen both in formulas?
Also, I would think that if the Laplacian doesn't include the mixed derivatives, then a surface that is concave up along the x and y axis but concave down on the diagonals y = x and y = -x should have a positive Laplacian. But if we change the basis vectors from pointing along the x and y axis to the diagonals y = x and y = -x, then wouldn't the surface now be concave down along the new axes so the Laplacian would become negative in the new basis?
It seems like the determinant of the Hessian would make more sense if we want to represent the 2nd derivative as just a scalar.
@0x484884 Good question. The Laplacian is invariant to a choice of coordinates. One way to understand this is that the Laplacian is the trace of the Hessian, and the trace is invariant to a choice of coordinates. (For instance, with an ordinary matrix the trace is equal to the sum of the eigenvalues, and eigenvalues are a geometric quantity that does not depend on coordinates.)