df(x_0) is the gradient and H(x_0) is the Hessian at point x_0. We can now minimize this function by taking its derivative with respect to x and setting the result to zero.
df(x_0) + H(x_0) x = 0
And solving for x gives us
x = -inv(H(x_0)) * df(x_0)
So using this quadratic approximation of our function, the minimum is at x_0 - inv(H(x_0)) * df(x_0). (Of course, since our function is not usually a quadratic, we need to repeat this procedure multiple times to converge to the correct solution.)
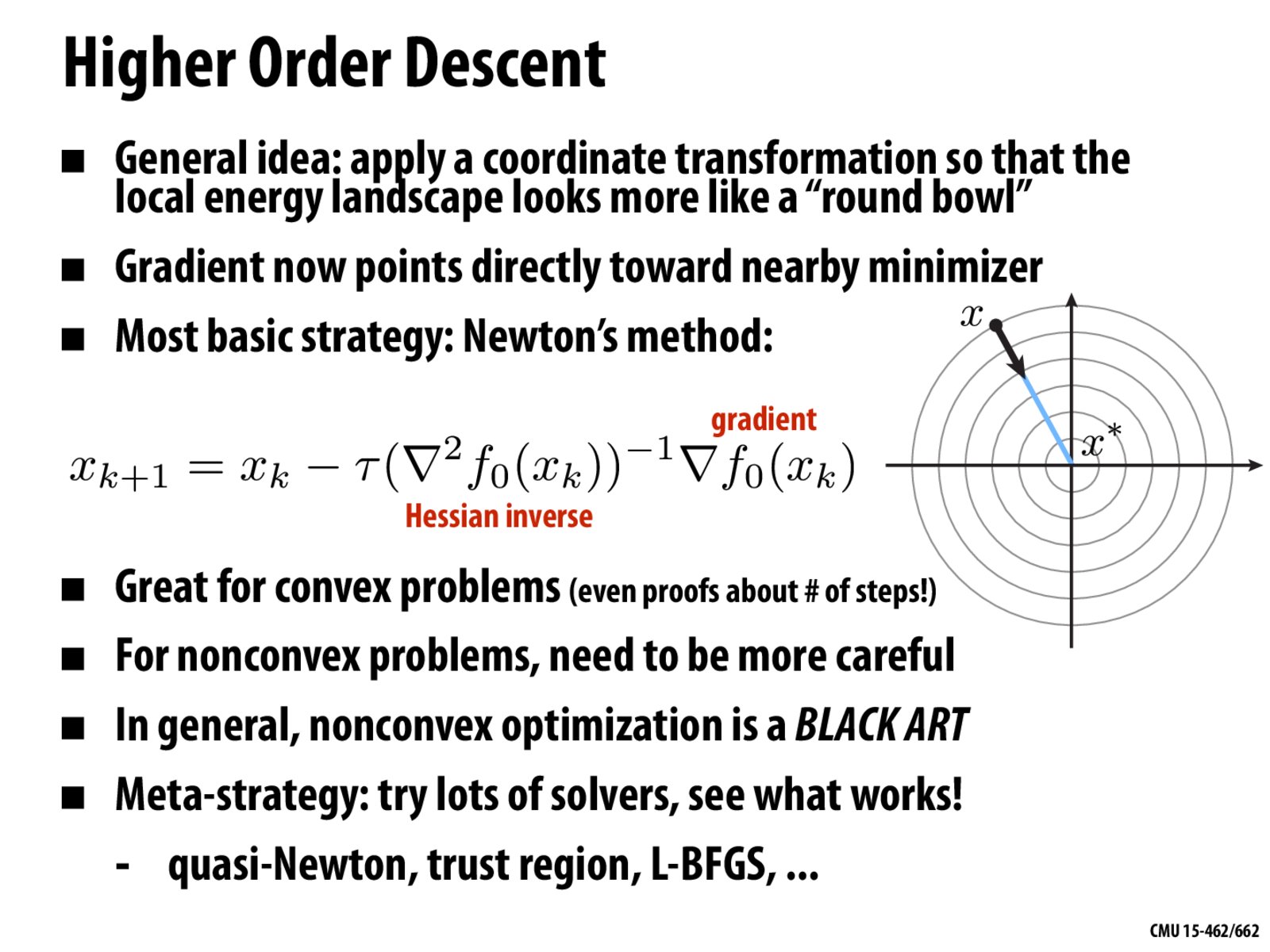
Is there any intuition as to why the inverse of the Hessian provides this coordinate change we desire?
@anonymous Newton's method comes from making a 2nd order (quadratic) approximation of our function
f(x)using the Taylor series expansion.df(x_0)is the gradient andH(x_0)is the Hessian at pointx_0. We can now minimize this function by taking its derivative with respect toxand setting the result to zero.And solving for
xgives usSo using this quadratic approximation of our function, the minimum is at x_0 - inv(H(x_0)) * df(x_0). (Of course, since our function is not usually a quadratic, we need to repeat this procedure multiple times to converge to the correct solution.)