We always end up at a minimum, but it may be a local minimum rather than a global minimum.
billiam
Why do we choose to use gradient descent over simplex method?
OtB_BlueBerry
I think simplex method is only for linear programming.
billiam
Lol you're right!
elenagong
How do we solve gradient descent for non-linear systems?
motoole2
@elenagong Well, if you can compute the gradient analytically, then (1) you compute the gradient at a point x_0, and (2) search along the gradient direction d for another point that minimizes your function f(x_0 - \alpha d). (See the next slide.) Otherwise, perhaps you can perform finite differencing at a point x_0 to estimate the gradient.
Tdog
Do we ever normalize the gradient?
SlimShady
I don't think we need to? because we have the step size to tune the magnitude, but correct me if I am wrong
motoole2
@Tdog @SlimShday Typically no---the classical gradient descent algorithm does not normalize the magnitude of the gradient. However, there is such a thing as normalized gradient descent, so there may be arguments to normalize.
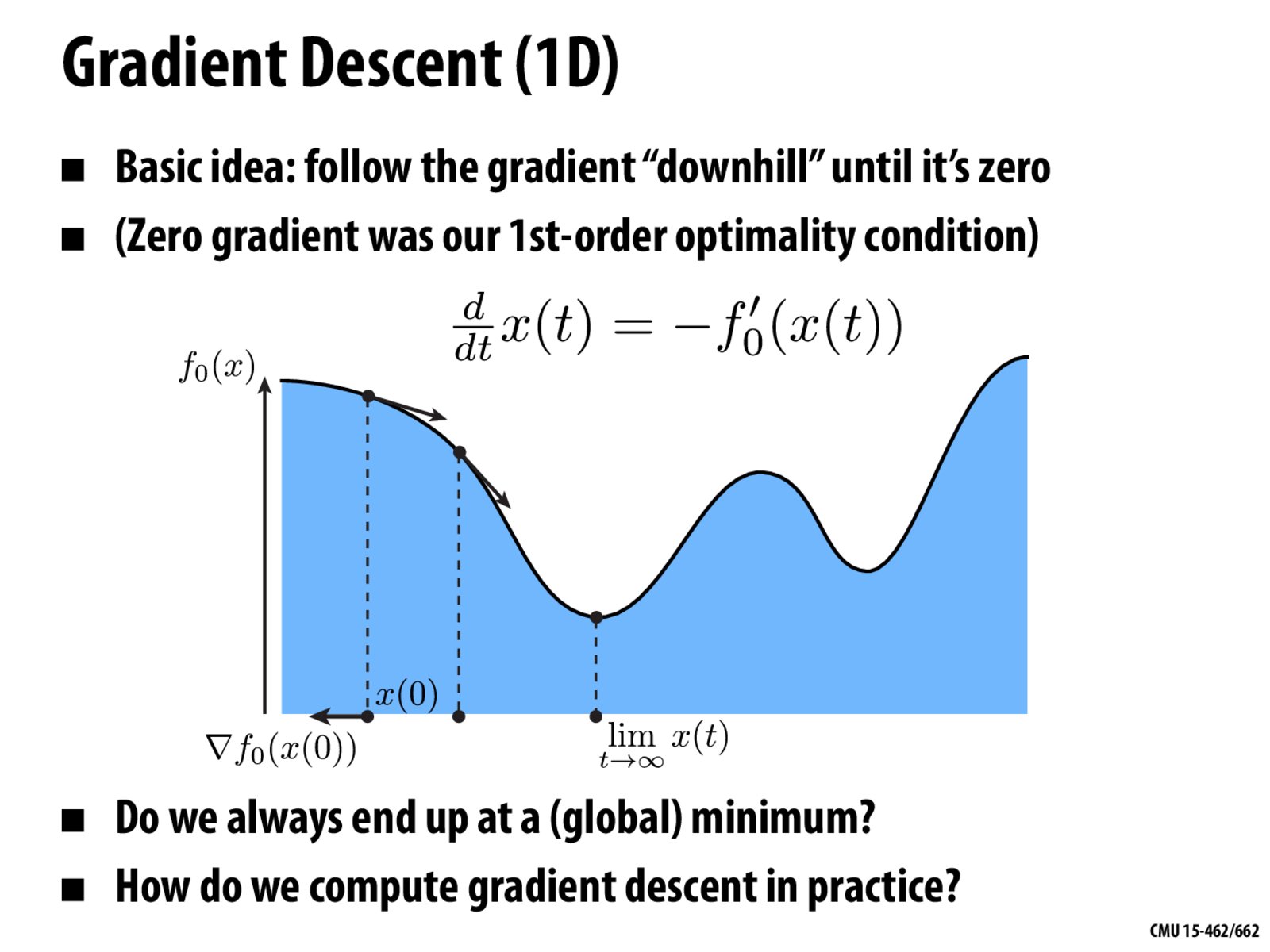
We always end up at a minimum, but it may be a local minimum rather than a global minimum.
Why do we choose to use gradient descent over simplex method?
I think simplex method is only for linear programming.
Lol you're right!
How do we solve gradient descent for non-linear systems?
@elenagong Well, if you can compute the gradient analytically, then (1) you compute the gradient at a point
x_0, and (2) search along the gradient directiondfor another point that minimizes your functionf(x_0 - \alpha d). (See the next slide.) Otherwise, perhaps you can perform finite differencing at a pointx_0to estimate the gradient.Do we ever normalize the gradient?
I don't think we need to? because we have the step size to tune the magnitude, but correct me if I am wrong
@Tdog @SlimShday Typically no---the classical gradient descent algorithm does not normalize the magnitude of the gradient. However, there is such a thing as normalized gradient descent, so there may be arguments to normalize.