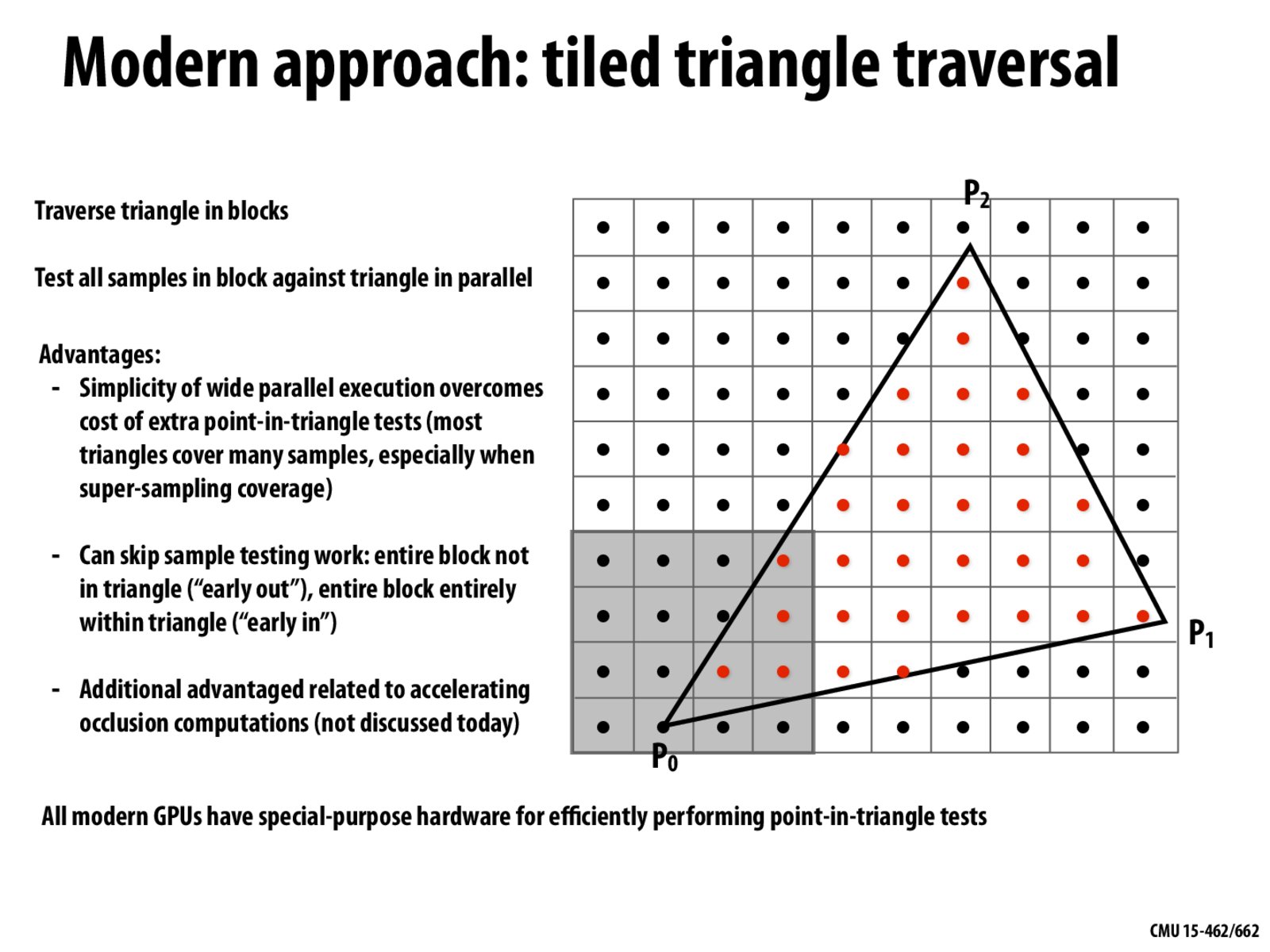
What is the size of the block? Is it user-defined? Or it depends on GPU? Is it the larger the faster?
motoole2
Hard question to answer, because it depends entirely on the GPU architecture. But tiles that are too large will certainly hurt performance. For example, the largest tile would cover the entire screen and result in a lot of wasteful computations.
jfondrie
Would tile size be some fixed area of pixels or do GPUs typically scale to make the tile some percent of the current screen resolution? In addition, would tile sizes ever dynamically change during the filling of some image?
I'm interested in understanding the parallelization of this approach in more detail. When there are a number of triangles to render, and obviously quite a few pixels to check for each triangle, will this process run in parallel for each triangle individually, AND within those, each process will run pixel tests (or whole blocks) in parallel? How do these then join again? Is that where occlusion is needed?
adrian_TA
@Kalecgos If you're particularly interested / motivated, check out these slides from 15-418, which go over some of the challenges in designing algorithms for the GPU:
What is the size of the block? Is it user-defined? Or it depends on GPU? Is it the larger the faster?
Hard question to answer, because it depends entirely on the GPU architecture. But tiles that are too large will certainly hurt performance. For example, the largest tile would cover the entire screen and result in a lot of wasteful computations.
Would tile size be some fixed area of pixels or do GPUs typically scale to make the tile some percent of the current screen resolution? In addition, would tile sizes ever dynamically change during the filling of some image?
While the exact approach used on modern GPUs is most likely proprietary info, here's a link to a super in-depth analysis of tile-based rasterization for different GPUs. It does appear that the size of tiles is fixed for some GPUs and can scale for other GPUs.
I'm interested in understanding the parallelization of this approach in more detail. When there are a number of triangles to render, and obviously quite a few pixels to check for each triangle, will this process run in parallel for each triangle individually, AND within those, each process will run pixel tests (or whole blocks) in parallel? How do these then join again? Is that where occlusion is needed?
@Kalecgos If you're particularly interested / motivated, check out these slides from 15-418, which go over some of the challenges in designing algorithms for the GPU:
http://www.cs.cmu.edu/~418/lectures/06_gpuarch.pdf