I don't understand how we could cut down the granularity of sampling? Pixel is the smallest possible render-able unit on the screen. But if we could render something smaller, we would already be working on that! Why would we ever show suboptimal results?
Or were we populating 4 pixels at a time with the same color when there was no supersampling?
keenan
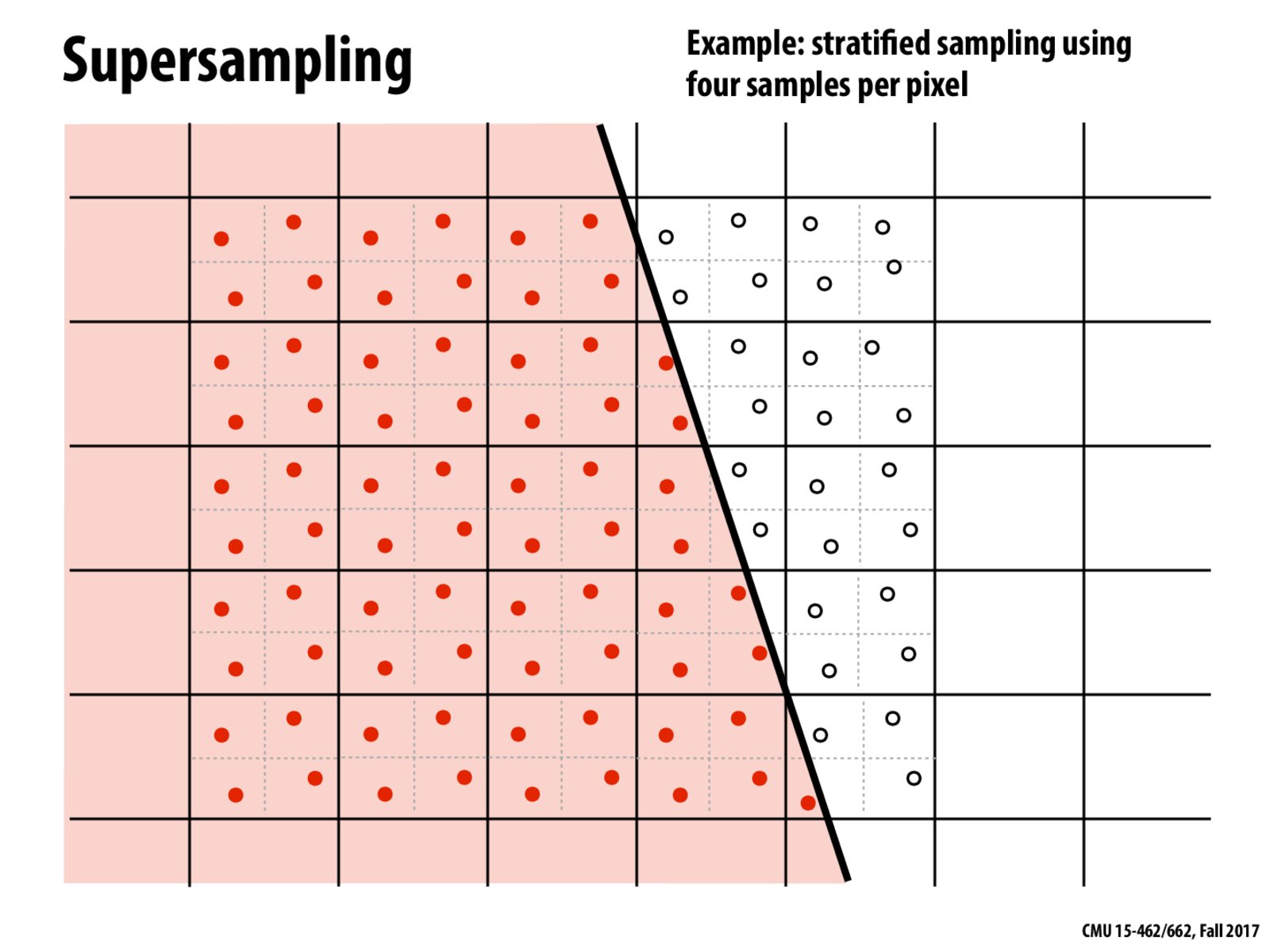
@pkukreja You may not be able to draw more pixels than what you have on the screen, but you can certainly store more pixel values in memory. For instance, you could first draw everything into a "virtual screen" (or "supersampling buffer") that's 2x as wide and 2x as tall; then to get the final pixel values, you would average each little 2x2 block (as depicted on the slide).
In real hardware, things get a lot more complicated! One observation, for instance, is that super-sampling color values are often not as important as super-sampling coverage values. So there may be special tricks that are used to get a better approximation of coverage, while still evaluating the color only once. This trick is especially useful if the color value depends on some complicated calculations (e.g., what's known as a "fragment shader" on the GPU).
I don't understand how we could cut down the granularity of sampling? Pixel is the smallest possible render-able unit on the screen. But if we could render something smaller, we would already be working on that! Why would we ever show suboptimal results?
Or were we populating 4 pixels at a time with the same color when there was no supersampling?
@pkukreja You may not be able to draw more pixels than what you have on the screen, but you can certainly store more pixel values in memory. For instance, you could first draw everything into a "virtual screen" (or "supersampling buffer") that's 2x as wide and 2x as tall; then to get the final pixel values, you would average each little 2x2 block (as depicted on the slide).
In real hardware, things get a lot more complicated! One observation, for instance, is that super-sampling color values are often not as important as super-sampling coverage values. So there may be special tricks that are used to get a better approximation of coverage, while still evaluating the color only once. This trick is especially useful if the color value depends on some complicated calculations (e.g., what's known as a "fragment shader" on the GPU).