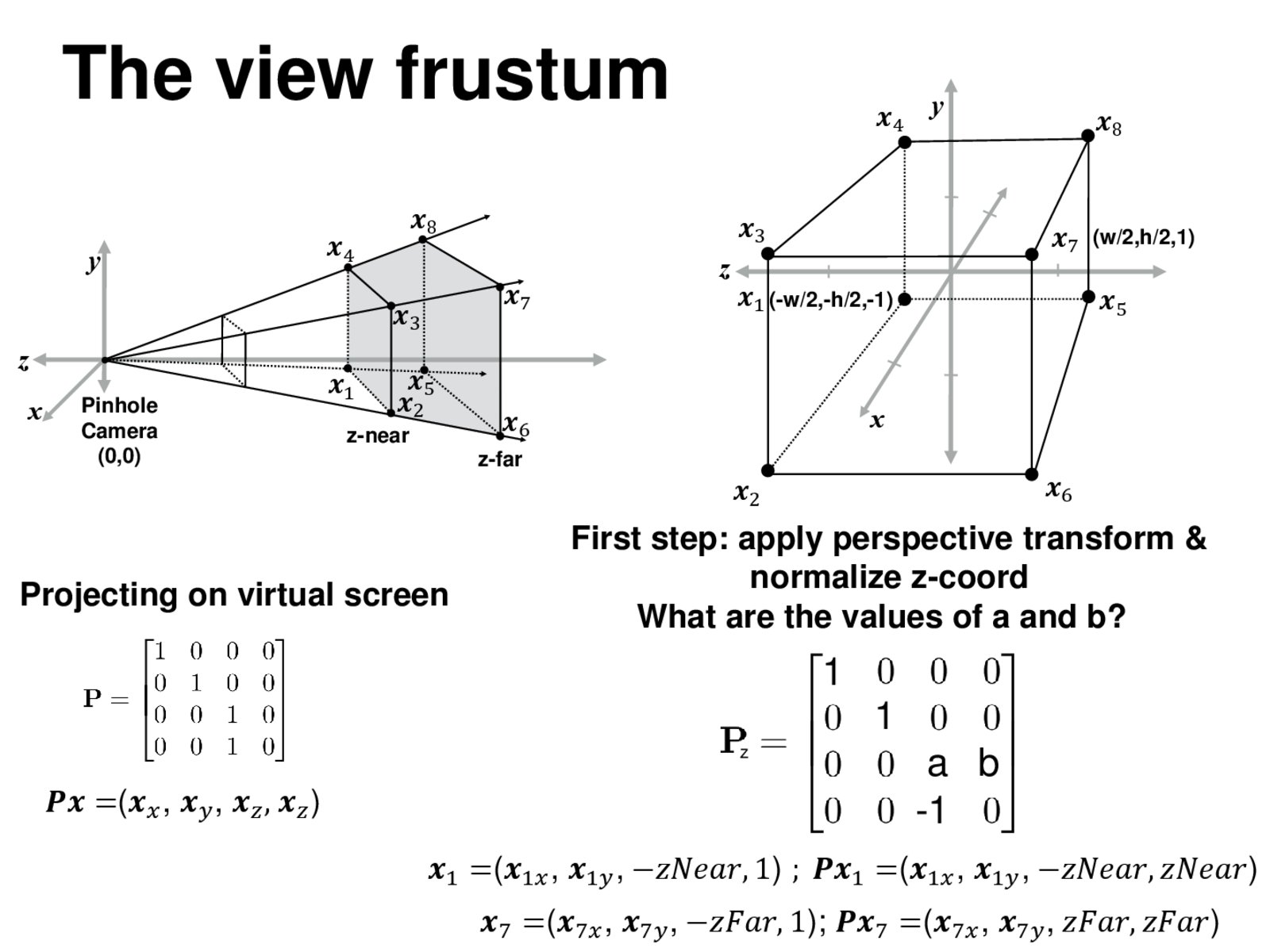
I'm not sure what the $P_z, Px_1$ are and what's their relationship to Px on the left (I know Px on the left is moving from 3D-H coordinate to 2D-H). Can anyone give me a hint?
Thanks.
scoros
Hmmm, there is a typo here, thanks for pointing it out. $P_z$ denotes the projection matrix that takes everything from the view frustum and maps it to a box whose z-coords are at -1 and 1. $P_zx_1$ isthe point that you get when you transform $x_1$ using this matrix.
Misaka-10032
It's not particular to $x_1$ and $x_7$ though. Idea is just to map
$(x, y, -zNear, 1)$ to $(x, y, -zNear, zNear)$
$(x, y, -zFar, 1)$ to $(x, y, zFar, zFar)$.
Whatever between $(x, y, -zNear, 1)$ and $(x, y, -zFar, 1)$ is convex combination of them, so the entire frustum will be mapped to the unit cube. $a, b$ can be solved by the following equations.
$$
-a \, zNear + b = -zNear \\
-a \, zFar + b = zFar
$$
Solve this and we have
$$
a = \frac{zNear + zFar}{zNear - zFar} \\
b = \frac{2 \, zNear \, zFar}{zNear - zFar}
$$
? The mapping in the slide is like having a reflection? Is it kind of convention that those with smaller $z$'s will override those with large $z$'s when it's rendering?
scoros
It's just a convention.
pchatrat
Why do we transform view frustum to unit cube? Is it because it will make rasterization easy?
keenan
It's because it makes clipping easy, i.e., because it makes it easier to determine if a triangle is outside the view frustum, and also much easier to actually compute the geometry of clipped (i.e., partial) triangles.
I'm not sure what the $P_z, Px_1$ are and what's their relationship to Px on the left (I know Px on the left is moving from 3D-H coordinate to 2D-H). Can anyone give me a hint?
Thanks.
Hmmm, there is a typo here, thanks for pointing it out. $P_z$ denotes the projection matrix that takes everything from the view frustum and maps it to a box whose z-coords are at -1 and 1. $P_zx_1$ isthe point that you get when you transform $x_1$ using this matrix.
It's not particular to $x_1$ and $x_7$ though. Idea is just to map
Whatever between $(x, y, -zNear, 1)$ and $(x, y, -zFar, 1)$ is convex combination of them, so the entire frustum will be mapped to the unit cube. $a, b$ can be solved by the following equations.
$$ -a \, zNear + b = -zNear \\ -a \, zFar + b = zFar $$
Solve this and we have
$$ a = \frac{zNear + zFar}{zNear - zFar} \\ b = \frac{2 \, zNear \, zFar}{zNear - zFar} $$
Thus, for this step
$$ P_1 = \begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & \frac{zNear + zFar}{zNear - zFar} & \frac{2 \, zNear \, zFar}{zNear - zFar} \\ 0 & 0 & -1 & 0 \end{pmatrix} $$
Question: why not map
? The mapping in the slide is like having a reflection? Is it kind of convention that those with smaller $z$'s will override those with large $z$'s when it's rendering?
It's just a convention.
Why do we transform view frustum to unit cube? Is it because it will make rasterization easy?
It's because it makes clipping easy, i.e., because it makes it easier to determine if a triangle is outside the view frustum, and also much easier to actually compute the geometry of clipped (i.e., partial) triangles.